


Scrapy 框架的 Shell 工具使用
今天我们来介绍和实战 Scrapy 框架的命令行模式,它和 Django 框架的 shell 模式一样,用于我们前期调试工程代码,非常方便,掌握好 Scrapy 的 shell 模式会使得我们开发爬虫更为顺畅。
1. Scrapy Shell 介绍
Scrapy Shell 是一个交互终端,类似于 Python 交互式模式,它使我们可以在未启动 Scrapy 爬虫的情况下调试爬虫代码。
在 Scrapy 的交互模式下,我们可以直接获取网页的 Response 结果,然后使用 XPath 或 CSS 表达式来获取网页元素,并以此测试我们获取网页数据的 Xpath 或者 CSS 表达式,确保后续执行时能正确得到数据。我们来看看如何进入 shell 模式,参考如下的视频:
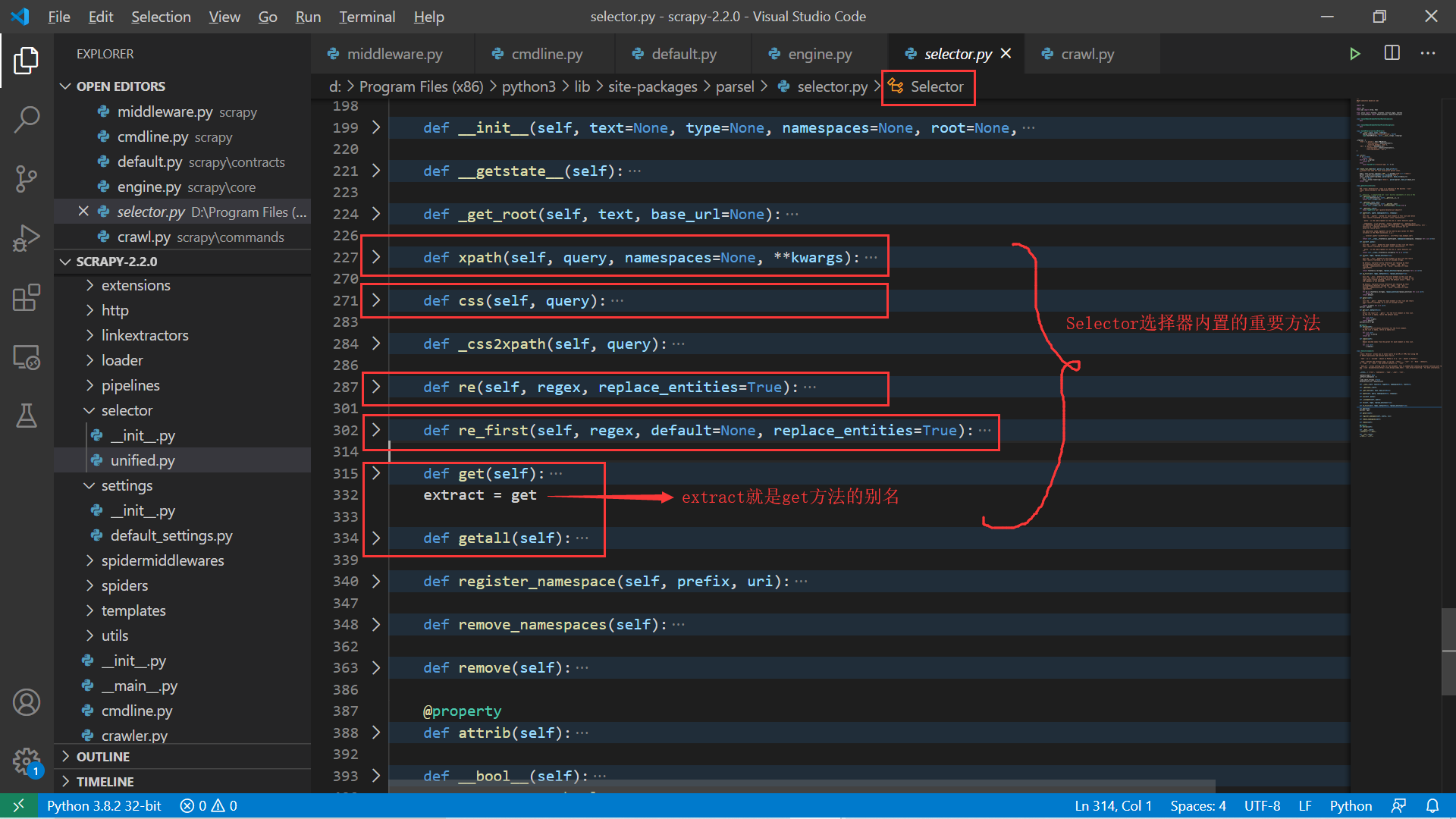
在 Scrapy 框架中内置了 Selector 选择器,这个选择器是属于 parsel 模块的,而 parsel 模块是由 Scrapy 团队为解析网页而开发的,并且独立出来形成了一个第三方模块。
这样我们可以在自己的爬虫程序中使用 parsel 模块而不必基于 Scrapy 框架 。我们从源码中来看看这个选择器类的定义。可以看到 Selector 类有我们熟悉的 xpath() 、css()、re() 以及 extract() 等方法,这些是我们解析网页的基础。
我们来思考一个问题,然后去源码中找到答案:
(scrapy-test) [root@server ~]# scrapy shell https://gz.lianjia.com/ershoufang/ --nolog
...
>>> type(response)
<class 'scrapy.http.response.html.HtmlResponse'>
我们在 Scrapy Shell 中可以看到 response 是 HtmlResponse 的一个实例,它是怎么会有 Selector 的方法的?我们在前面的 Scrapy 初步的实例中看到过 response.xpath() 这样的用法,源码里面是怎么做的呢?
这个问题比较简单,我们翻看一下源码就可以找到答案了。首先查看 HtmlResponse 类定义:
# 源码位置:scrapy/http/response/html.py
from scrapy.http.response.text import TextResponse
class HtmlResponse(TextResponse):
pass
这个够不够简单?继续追看 TextResponse 的定义:
# 源码位置:scrapy/http/response/text.py
# ...
class TextResponse(Response):
# ...
@property
def selector(self):
from scrapy.selector import Selector
if self._cached_selector is None:
self._cached_selector = Selector(self)
return self._cached_selector
# ...
def xpath(self, query, **kwargs):
return self.selector.xpath(query, **kwargs)
def css(self, query):
return self.selector.css(query)
# ...
是不是一下子就明白了?response.xpath() 正是调用的 scrapy.selector 下的Selector,继续看这个 Selector 的定义:
# 源码位置:scrapy/selector/unified.py
from parsel import Selector as _ParselSelector
class Selector(_ParselSelector, object_ref):
# ...
是不是最后又到了 parsel 下的 Selector?所以使用 response.xpath() 等价于使用 parsel 模块 下的 Selector 类中的 xpath 方法去定位网页元素。在给大家留一个更进一步的问题:
在前面爬取互动出版网的 Scrapy 框架实例中,我们还用到了这样的表达式:
book.xpath().extract()[0]和book.xpath().extract_first(),这样的代码执行过程又是怎样的呢(追踪到 parsel 这一层即可)?
这个问题追踪的代码会比上面多一点,但也不复杂,这个问题会在下一节的 Reponse 类分析中给出相应的回答。
2. Scrapy Shell 实战
上面介绍了一些 Scrapy Shell 和 Response 的基础知识,我们现在就来在 Scrapy Shell 中实战 Selector 选择器。本次测试的网站为广州链家,测试页面为二手房页面:
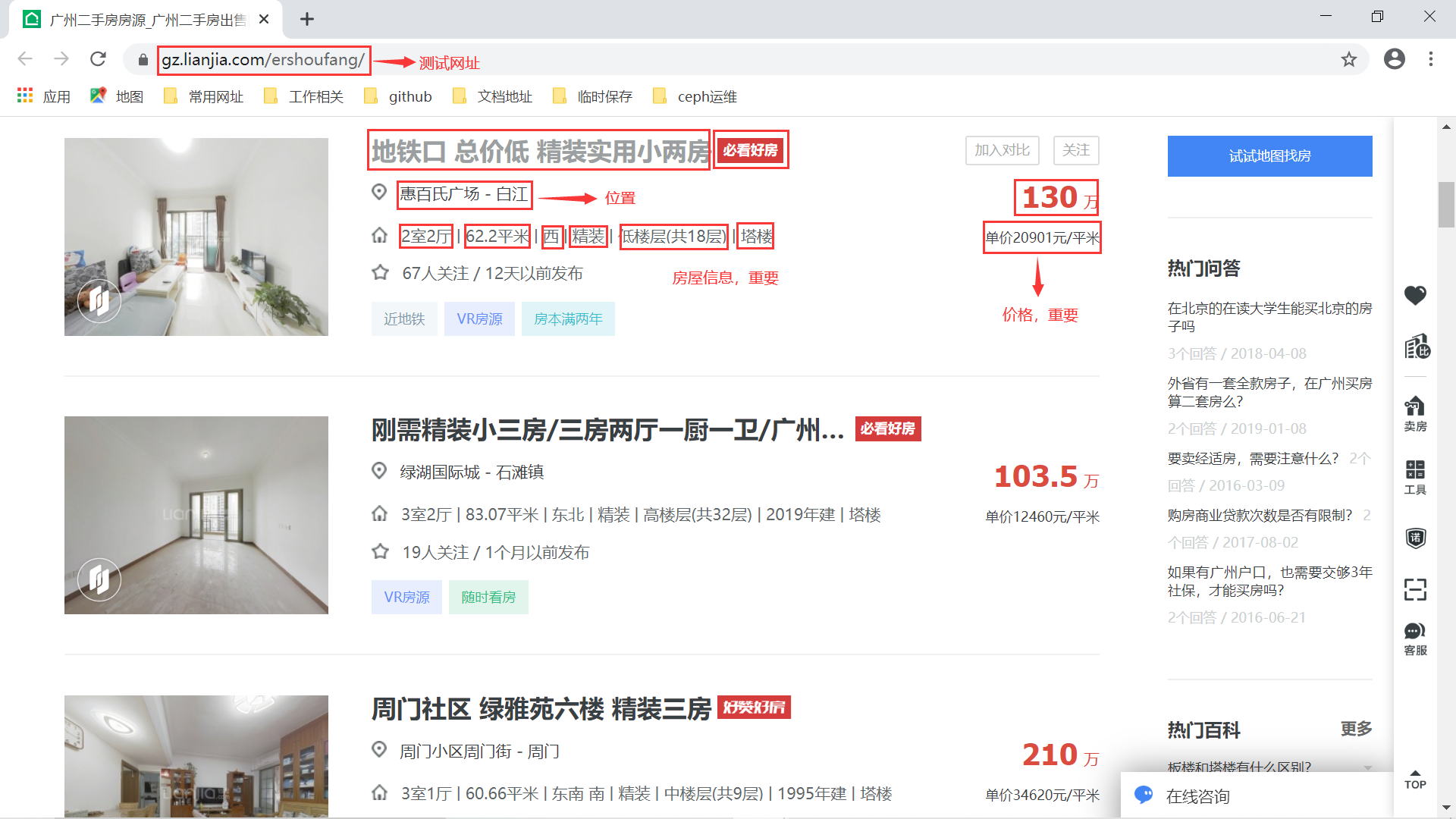
我已经在上面标出了想要爬取的网页信息,后面也主要测试这些数据的 xpath 表达式 或者 css 表达式。首先使用 scrapy shell 目标网址 命令进行想要的命令行,此时 Scrapy 框架已经为我们将目标网站的网页数据爬取了下来:
(scrapy-test) [root@server ~]# scrapy shell https://gz.lianjia.com/ershoufang/
...
>>> response
<200 https://gz.lianjia.com/ershoufang/>
我们看到响应的网页数据已经有了,接下来我们就可以开始进行网页分析来抓取图片中标记的数据了。首先是标题信息: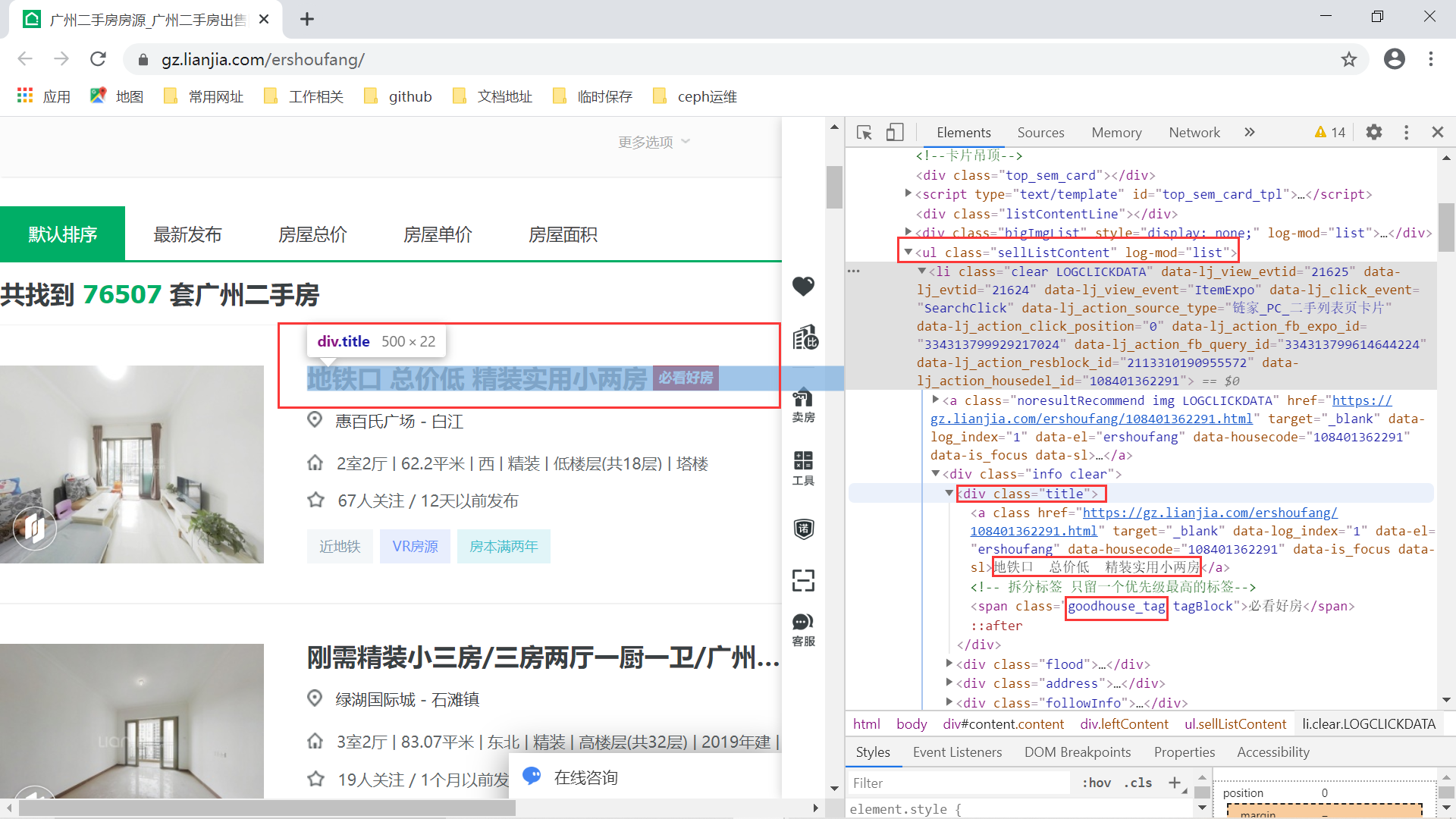
根据上面的网页结构,可以很快得到标题的 xpath 路径表达式:
标题://ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()
在 Scrapy Shell 中我们实战一把:
>>> response.xpath('//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()')
[<Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='地铁口 总价低 精装实用小两房'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='刚需精装小三房/三房两厅一厨一卫/广州东绿湖国际城'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='周门社区 绿雅苑六楼 精装三房'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='金碧领秀国际 精装修一房 中楼层采光好'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='户型方正 采光好 通风透气 小区安静'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='毛纺小区 南向两房 方正实用 采光好'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='南奥叠层复式 前后楼距开阔 南北对流通风好'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='丹桂园 实用三房精装修 南向户型 拧包入住'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='周门小区大院管理 近地铁总价低全明正规一房一厅'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='云鹤北街 精装低楼层 南向两房'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='中海誉城东南向两房,住家安静,无抵押交易快'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='精装两房,步梯中层,总价低,交通方便,配套齐全'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='中层南向四房 格局方正 楼层适中'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='精装修 户型好 中空一房 采光保养很好'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='业主急售,价格优质看房方便有密码'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='汇侨新城北区 精装三房 看花园 户型靓'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='小区中间,安静,前无遮挡,视野宽阔,望别墅花园'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='小区侧边位 通风采光好 小区管理 装修保养好'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='万科三房 南北对流 中高层采光好'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='南北对流,采光充足,配套设施完善,交通便利'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='美力倚睛居3房南有精装修拎包入住'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='美心翠拥华庭二期 3室2厅 228万'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='天河公园门口 交通便利 配套成熟'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='保利香槟花园 高层视野好 保养很好 居家感好'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='恒安大厦两房,有公交,交通方便,价格方面可谈'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='此房是商品房,低层,南北对流,全明屋'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='水荫直街 原装电梯户型 方正三房格局'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='嘉诚国际公寓 可明火 正规一房一厅'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='近地铁两房 均价低 业主自住 装修保养好'>, <Selector xpath='//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()' data='宏城汇 三房 南向 采光好 户型方正 交通便利'>]
上面结果返回的是 SelectorList 类型:
>>> data_list = response.xpath('//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()')
>>> type(data_list)
<class 'scrapy.selector.unified.SelectorList'>
最后我们通过提取 Selector 的 root 属性,只得到相应的文本信息:
>>> data = [d.root for d in data_list]
>>> data
['地铁口 总价低 精装实用小两房', '刚需精装小三房/三房两厅一厨一卫/广州东绿湖国际城', '周门社区 绿雅苑六楼 精装三房', '金碧领秀国际 精装修一房 中楼层采光好', '户型方正 采光好 通风透气 小区安静', '毛纺小区 南向两房 方正实用 采光好', '南奥叠层复式 前后楼距开阔 南北对流通风好', '丹桂园 实用三房精装修 南向户型 拧包入住', '周门小区大院管理 近地铁总价低全明正规一房一厅', '云鹤北街 精装低楼层 南向两房', '中海誉城东南向两房,住家安静,无抵押交易快', '精装两房,步梯中层,总价低,交通方便,配套齐全', '中层南向四房 格局方正 楼层适中', '精装修 户型好 中空一房 采光保养很好', '业主急售,价格优质看房方便有密码', '汇侨新城北区 精装三房 看花园 户型靓', '小区中间,安静,前无遮挡,视野宽阔,望别墅花园', '小区侧边位 通风采光好 小区管理 装修保养好', '万科三房 南北对流 中高层采光好', '南北对流,采光充足,配套设施完善,交通便利', '美力倚睛居3房南有精装修拎包入住', '美心翠拥华庭二期 3室2厅 228万', '天河公园门口 交通便利 配套成熟', '保利香槟花园 高层视野好 保养很好 居家感好', '恒安大厦两房,有公交,交通方便,价格方面可谈', '此房是商品房,低层,南北对流,全明屋', '水荫直街 原装电梯户型 方正三房格局', '嘉诚国际公寓 可明火 正规一房一厅', '近地铁两房 均价低 业主自住 装修保养好', '宏城汇 三房 南向 采光好 户型方正 交通便利']
是不是非常简单就爬到了数据?另外,我们还可以使用 extract()[0] 或者 extract_first() 这样的方式来提取结果列表中的第一个文本数据:
>>> data = response.xpath('//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()').extract()[0]
>>> data2 = response.xpath('//ul[@class="sellListContent"]/li/div/div[@class="title"]/a/text()').extract_first()
>>> data == data2
True
>>> data
'地铁口 总价低 精装实用小两房'
接下来,我们依次找出获取二手房位置、房屋价格、房屋信息的 xpath 路径表达式:
房屋位置:
//ul[@class="sellListContent"]/li/div/div[@class="food"]/div[@class="positionInfo"]/a[]/text()
房屋信息:
//ul[@class="sellListContent"]/li/div/div[@class="address"]/div[@class="houseInfo"]/text()
房屋价格:
//ul[@class="sellListContent"]/li/div/div[@class="priceInfo"]/div[@class="totalPrice"]/span/text()
有了这些之后,我们就可以依次提取出二手房的【标题介绍】、【房屋位置】、【房屋信息】以及【房屋价格】这些信息。此外对于提取的【房屋信息】字段还要进一步处理,分割成【房屋结构】、【房屋大小】以及【朝向】等信息。这些信息将在 Spider 模块中进行提取,也就是我们前面互动出版网爬虫的 ChinaPubCrawler.py 文件中的 ChinaPubCrawler 类来解析。
最后我们在介绍下 scrapy shell 命令的参数:
(scrapy-test) [root@server ~]# scrapy shell --help
Usage
=====
scrapy shell [url|file]
Interactive console for scraping the given url or file. Use ./file.html syntax
or full path for local file.
Options
=======
--help, -h show this help message and exit
-c CODE evaluate the code in the shell, print the result and
exit
--spider=SPIDER use this spider
--no-redirect do not handle HTTP 3xx status codes and print response
as-is
Global Options
--------------
--logfile=FILE log file. if omitted stderr will be used
--loglevel=LEVEL, -L LEVEL
log level (default: DEBUG)
--nolog disable logging completely
--profile=FILE write python cProfile stats to FILE
--pidfile=FILE write process ID to FILE
--set=NAME=VALUE, -s NAME=VALUE
set/override setting (may be repeated)
--pdb enable pdb on failure
比较常用的有 --no-redirect 和 -s 选项:
--no-redirect: 指的是不处理重定向,直接按照原始响应返回即可;-s:替换settings.py中的配置。常用的有设置USER_AGENT等。
3. 小结
本小节中我们简单介绍了 Scrapy 的 Shell 模式以及 Response 类的一些原理。紧接着我们开始了 Scrapy Shell 实战,以广州链家网为例,测试在 Shell 模式下使用 Selector 选择器来解析网页数据,提取房屋标题、位置、价格等数据。下面一节我们会深入分析 Scrapy 框架中的 Request 和 Response ,包括解答今天的一个源码追踪作业。
- 还没有人评论,欢迎说说您的想法!
 客服
客服


