


Scrapy 中的中间件
今天我们来聊一聊 Scrapy 框架中的中间件使用,包括 Spider 中间件、下载中间件等。它属于 Scrapy 框架的一个重要部分,是我们定制化 Scrapy 框架时的重要基础。
1. Spider 中间件
1.1 Spider 中间件介绍
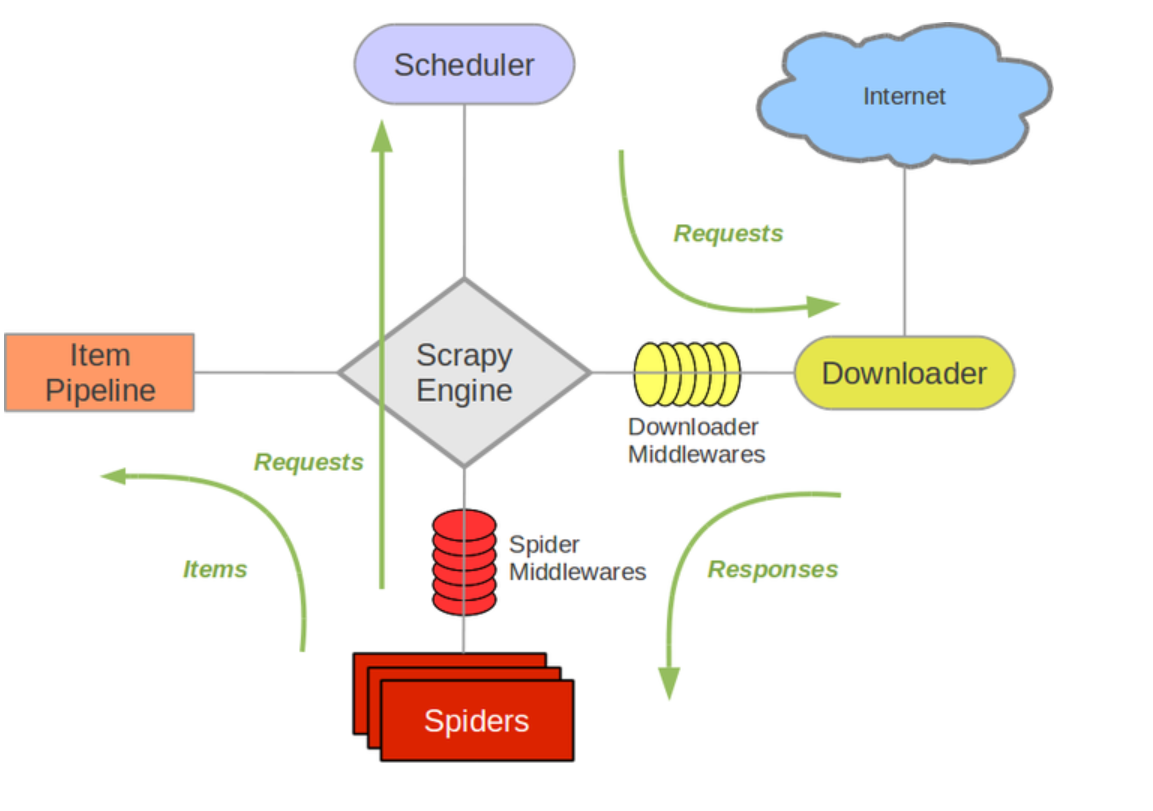
我们从架构图中可以看到,Spider 中间件(Spider Middlewares)位于引擎模块和 Spiders 中间,通过这个中间件模块我们可以控制发送给 Spider 的 Response 以及 Spider 传回给引擎的 Items 和 Requests。使用 Spider 中间件的第一步是要在配置文件中启用它,启用方式只需要设置 SPIDER_MIDDLEWARES 的值即可:
SPIDER_MIDDLEWARES = {
# 指定编写的Spider中间件类的位置
'myproject.middlewares.CustomSpiderMiddleware': 543,
}
自定义在 settings.py 中的 Spider 中间件会和 Scrapy 内置的 SPIDER_MIDDLEWARES_BASE 设置合并,然后根据对应的 value 值进行排序,得到最终的 Spider 中间件的有序执行列表:值最小的最靠近引擎那一侧,值最大的最靠近 Spider。
我们来看 Scrapy 内置的 SPIDER_MIDDLEWARES_BASE 值如下所示。上面设置的 543 正好使得自定义的 CustomSpiderMiddleware 中间件位于 OffsiteMiddleware 中间件和 RefererMiddleware 中间件之间。
# 源码位置:scrapy/settings/default_settings.py
SPIDER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800,
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
# Spider side
}
当我们想禁止相应的 Spider 中间件时,只需要在 SPIDER_MIDDLEWARES 中将对应的中间件的值设置为 None 即可:
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': None,
}
1.2 编写 Spider 中间件
编写 Scrapy 中自定义的 Spider 中间件非常简单,每个中间组件都是实现了以下一个或者多个方法的 Python 类:
- process_spider_input(response, spider):对于通过 Spider 中间件并进入 Spider 进行处理的每个 response,都会调用此方法。该方法返回 None 或者抛出异常,如果返回的是 None,Scrapy 将继续处理这个响应,执行所有其他的 Spider 中间件,直到最后,响应被交给 Spider 进行处理;如果是抛出了一个异常,则会调用下面的 process_spider_exception() 方法处理而不会在调用其他的 Spider 中间件;
- process_spider_output(response, result, spider):这个方法一般会在 Spider 处理完响应后调用,也就是我们前面编写的 parse() 或者自定义的 parse_xxx() 方法执行完后调用;
- process_spider_exception(response, exception, spider):当 spider 或者 上一个 spider 中间件的 process_spider_output() 抛出异常时会调用该方法;
- process_start_requests(start_requests, spider):此方法与 spider 的开始请求一起调用,其工作方式与 process_spider_output() 方法类似,只不过它没有关联的 response,且只返回请求 (而不是 items)。
注意:我们一般实现的自定义中间件类会写在 scrapy 项目的 middlewares.py 中,当然也可以写到任意的代码文件中,只需要在写入配置时指定好完整的类路径即可。
1.3 Scrapy 中内置的 Spider 中间件
接下来,我们来看看 Scrapy 中内置的 Spider 中间件,目前最新的 Scrapy-2.2.0 中一共有 5 个内置的 Spider 中间件:

我们来分别介绍下这 5 个内置的 Spider 中间件,如果能利用好这些中间件以及进行合理的配置,可以简化不少代码和提高网站爬取的成功率和效率。
DepthMiddleware
爬取深度中间件,该中间件用于追踪被爬取网站中每个 Request 的爬取深度。通过对该中间件相关参数的设置,可以限制爬虫爬取的最大深度,且可以根据深度控制请求的优先级等。该中间件对应的参数设置有:
- DEPTH_LIMiT:允许爬取的最大深度,如果为0,则不限制;
- DEPTH_STATS:是否收集爬取深度统计数据;
- DEPTH_PRIORITY:是否根据 Request 深度对其安排相应的优先级进行处理。
HttpErrorMiddleware
该中间件的作用是过滤掉所有不成功的 HTTP 响应,但这会增加开销,消耗更多的资源,并使 Spider 逻辑更加复杂;
根据 HTTP 标准,响应码在 200~300 之间都是成功的响应。如果想处理这个范围之外的 Response,可以通过 Spider 的 handle_httpstatus_list 属性值或者配置文件中的 HTTPERROR_ALLOWED_CODES 值来指定 Spider 能处理的 Response 状态码:
class MySpider(CrawlSpider):
handle_httpstatus_list = [404]
例如上面这样的写法就是只处理响应码为 404 的 Response。此外 HttpErrorMiddleware 中间件的配置值有两个,分别为:
- HTTPERROR_ALLOWED_CODES:默认值为[],传递此列表中包含的非200状态代码的所有响应;
- HTTPERROR_ALLOW_ALL:默认为 False,传递所有的 Response而不考虑其状态响应码的值。
OffsiteMiddleware
过滤请求中间件。用于过滤掉所有 Spider 覆盖主机域名外的 URL 请求;
RefererMiddleware
位置参考中间件。它的作用是根据生产的 Response 的 URL 来填充 Request Referer 信息;
UrlLengthMiddleware
网址长度限制中间件。它用于过滤 URL 长度大于 URLLENGTH_LIMIT 的值得 Request;
在 scrapy/settings/default_settings.py 中我们可以看到这样的配置:
SPIDER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800,
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
# Spider side
}
这些 Spider 中间件都默认启用,且从 Engine 端到 Spider 端的顺序如上配置所示。如果想禁止某个内置的 Spider 中间件,我们直接在 settings.py 文件中将该 Spider 的值设置为 None 即可,示例如下:
# 配置位置: 爬虫项目/settings.py
SPIDER_MIDDLEWARES = {
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': None,
}
2. 下载中间件
2.1 下载中间件介绍
从前面的 Scrapy 架构图图中可知,下载中间件(Downloader Middlewares)是位于 Scrapy 引擎(Scrapy Engine)和下载器(DownLoader)之间的,用于处理请求以及响应的中间层。
它可以全局修改 Scrapy 的请求和响应。那么如何激活下载中间件呢?假设我们编写了一个中间件类:我们只需要将其加入全局配置文件 (settings.py) 中即可:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
}
DOWNLOADER_MIDDLEWARES 中的 key 就是定义的下载中间件类,而 value 就是控制该中间件执行顺序的值,可以简单理解为表示该中间件执行的优先级。
值越小的越靠近 Scrapy 引擎,值越大越靠近下载器。我们在自定义下载中间件时,也需要考虑给自定义的下载中间件设置合理的值。因此,我们先看看 Scrapy 框架默认启用的下载中间件情况:
# 源码位置:scrapy/settings/default_settings.py
# ...
DOWNLOADER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
# Downloader side
}
# ...
如何不想启动默认的某个内置中间件时,同样只需要在 settings.py 中覆盖其值并设置为 None,即可禁用该下载中间件:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
了解了这些后,我们来看看如何编写自定义的下载中间件。
2.2 编写下载中间件
编写自定义的下载中间件也非常简单,只需要在自定义的类中实现一个或多个特定名字的方法即可。现在来介绍下下载中间件中那些特定方法:
process_request(request, spider)
当 Request 请求经过下载中间件时会调用该方法。该方法只能返回 None、Response 对象、Request 对象或者 IgnoreRequest 异常的其中之一。如果返回 None,Scrapy 将执行其他中间件中相应的方法继续处理该 Request,直到该 Request 被下载器的处理函数处理;如果返回 Response 对象,则 Scrapy 将直接返回该 Response,而不再继续调用原链路上的其他中间件的 process_request(),process_exception()或相应的下载方法,但是会依次调用已启用的中间件的 process_request() 方法;
process_response(request, response, spider)
在请求的 Response 经过下载中间件时会调用该方法。该方法返回 Response 对象、Request 对象或者是抛出 IgnoreRequest 异常。如果返回的是 Response 对象,则该 Response 会被其他中间件的 process_response() 方法处理;如果其返回的是一个 Request 对象,那么其余的下载中间件将不会处理,返回的 Request 会被引擎重新调度去下载;如果是抛出异常,则调用 Request.errback。如果没有相应的代码处理该异常,则忽略该异常;
process_exception(request, exception, spider)
在下载处理器或者下载中间件的 process_request() 方法抛出异常时,Scrapy 将调用该方法进行处理。该方法必须返回为 None、Response 对象以及 Request 对象三者之一;
以上这些关于下载中间件的特定函数的输入和输出信息我们可以在官方文档中找到详细的解答。上面的介绍主要是翻译了官方文档对这些方法的说明。后面我们也会在学习源码中找到这些输出输出的逻辑。
2.3 内置的下载中间件
同样,在 Scrapy 中为我们内置了不少的下载中间件,可以方便地配置下载参数,比如 Cookie、代理等。我们现在来介绍一些常用的下载中间件。
CookiesMiddleware:该中间件主要用于给请求加上 Cookie,这样可以方便我们的爬虫程序使用 Cookie 去访问网站。它记录了向 Web Server 发送的 Cookie,并在之后的 Request 请求中带上该 Cokkile,就像我们操作浏览器那样。该中间件在 settings.py 中的配置有2个:
-
COOKIES_ENABLE:默认为 True,表明启用 cookies 中间件,如果为 False,则不会使用 cookies。
Tips:如果
Request.meta参数的dont_merge_cookies的值为 True,那么无论 COOKIES_ENABLE 指定为何值,cookies 在这个请求的来回中都不会做任何处理; -
COOKIES_DEBUG:默认为 False。如果为 True,则会记录所有请求发送的 cookies 和响应接收到的 cookies;
HttpProxyMiddleware:该中间件通过在 Request.meta 中添加 proxy 属性值为该请求设置 HTTP 代理;
HttpCacheMiddleware:该中间件为所有 HTTP 请求和响应提供 low-level 缓存,它需要和缓存存储后端以及缓存的策略相结合;
DefaultHeadersMiddleware:该中间件通过配置文件中 DEFAULT_REQUEST_HEADERS 的值来设置所有请求默认的请求头;
DownloadTimeoutMiddleware:该中间件主要用来设置下载超时时间。对应 settings.py 中的配置值为:DOWNLOAD_TIMEOUT或者 spider 的 download_timeout 属性
好了,常用的下载中间件就介绍这么多了,其余的可以继续参考官方文档,写的非常详细。
3. 小结
本小节中分别从三个角度介绍了 Scrapy 中的 Spider 中间件和 下载中间件:中间件介绍、如何编写相应的中间件以及 Scrapy 内置的相应中间件。在理解了这些后,我们在下面两节会使用一个例子来对前面学到的知识进行实战演练,达到即学即用的目的。

- 还没有人评论,欢迎说说您的想法!
 客服
客服


