


Scrapy 配置介绍及常见优化配置
今天我们来看看 Scrapy 框架的相关配置项以及常见的一些优化配置。涉及的文件主要是 scrapy 项目的 settings.py 文件和 Scrapy 源码目录下的 scrapy/settings/default_settings.py 文件。这些内容会在我们每个 Scrapy 爬虫项目中都会用到,特别是在爬取海量数据时需要特别注意的地方。
1. Scrapy 的 settings.py 配置
从前面的学习中我们知道,settings.py 是 Scrapy 使用 startproject 命令生成的,这里的配置会默认覆盖 Scrapy 内置的配置项,这些默认的配置项都位于 Scrapy 的 scrapy/settings/default_settings.py 中:
我们来看看 default_settings.py 中的一些默认配置项。
-
AJAXCRAWL_ENABLED:通用爬取经常会抓取大量的 index 页面;AjaxCrawlMiddleware 能帮助我们正确地爬取,AJAXCRAWL_ENABLED配置正是开启该中间件的开关。由于有些性能问题,且对于特定爬虫没有什么意义,该中间默认关闭; -
自动限速扩展 (AutoThrottle):这类配置主要是以 Scrapy 爬虫以及正在抓取网站的负载来自动优化爬取速度。它能自动调整 Scrapy 达到最佳的爬取速度,使用者无需自己设置下载延迟,只要设置好最大并发请求数即可。来看看有关该扩展的配置项:
AUTOTHROTTLE_ENABLED = False # 默认关闭 AUTOTHROTTLE_DEBUG = False # 关闭调试 AUTOTHROTTLE_MAX_DELAY = 60.0 # 最高下载延迟 AUTOTHROTTLE_START_DELAY = 5.0 # 初始化下载延迟 AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Scrapy 同时请求目标网站的平均请求数
下面四个配置用于设置爬虫自动关闭条件:
CLOSESPIDER_TIMEOUT:一个整数值,单位为秒。如果一个 spider 在指定的秒数后仍在运行, 它将以closespider_timeout的原因被自动关闭。 如果值设置为0 (或者没有设置),spiders 不会因为超时而关闭;CLOSESPIDER_ITEMCOUNT:一个整数值,指定条目的个数。如果 spider 爬取条目数超过了设置的值, 并且这些条目通过 item pipelines 传递,spider 将会以closespider_itemcount的原因被自动关闭;CLOSESPIDER_PAGECOUNT:一个整数值,指定最大的抓取响应 (reponses) 数。 如果 spider 抓取数超过指定的值,则会以closespider_pagecount的原因自动关闭。 如果设置为0(或者未设置),spiders不会因为抓取的响应数而关闭;CLOSESPIDER_ERRORCOUNT:一个整数值,指定spider可以接受的最大错误数。 如果spider生成多于该数目的错误,它将以closespider_errorcount的原因关闭。 如果设置为0(或者未设置),spiders不会因为发生错误过多而关闭;
以上四个参数在 default_settings.py 中设置的默认值都是0
并发相关,的设置会较大影响 Scrapy 爬虫的性能。下面是默认的配置值,其中都已经进行了详细的注释说明:
# pipelines中并发处理items数
CONCURRENT_ITEMS = 100
# scrapy中并发下载请求数
CONCURRENT_REQUESTS = 16
# 对任何单个域执行的并发请求的最大数量
CONCURRENT_REQUESTS_PER_DOMAIN = 8
# 将对任何单个IP执行的并发请求的最大数量。如果非零
CONCURRENT_REQUESTS_PER_IP = 0
Cookie相关配置:
# 是否启用cookiesmiddleware。如果关闭,cookies将不会发送给web server
COOKIES_ENABLED = True
# 如果启用,Scrapy将记录所有在request(cookie 请求头)发送的cookies及response接收到的cookies(set-cookie接收头),这也会间接影响性能,因此默认关闭。
COOKIES_DEBUG = False
请求深度相关配置,比如 DEPTH_LIMIT 设置请求允许的最大深度。如果为 0 ,则表示不受限;DEPTH_STATS_VERBOSE 参数控制是否收集详细的深度统计信息;如果启用此选项,则在统计信息中收集每个深度的请求数。DEPTH_PRIORITY 参数用于根据深度调整请求优先级。来看看他们的默认设置:
DEPTH_LIMIT = 0
DEPTH_STATS_VERBOSE = False
DEPTH_PRIORITY = 0
DNS 相关配置。DNSCACHE_ENABLED 用于控制是否启用 DNS 缓存,DNSCACHE_SIZE参数设置缓存大小,DNS_TIMEOUT 处理 DNS 查询超时时间;我们来具体看看 default_settings.py 中的默认配置:
DNSCACHE_ENABLED = True
DNSCACHE_SIZE = 10000
# 缓存解析器
DNS_RESOLVER = 'scrapy.resolver.CachingThreadedResolver'
DNS_TIMEOUT = 60
下载器相关。这部分的配置比较多,也是主要影响性能的地方。我们对一些关键的配置进行说明,具体如下:
DOWNLOAD_DELAY:下载器在从同一网站下载连续页面之前应等待的时间,通过该配置可以限制爬虫的爬取速度。此外,该设置也受RANDOMIZE_DOWNLOAD_DELAY 设置(默认情况下启用)的影响。DOWNLOAD_TIMEOUT:下载超时时间;DOWNLOAD_MAXSIZE:下载器将下载的最大响应大小;DOWNLOAD_HANDLERS_BASE:处理不同类型下载的下载器;DOWNLOAD_FAIL_ON_DATALOSS:数据丢失后是否继续下载;DOWNLOADER_MIDDLEWARES和DOWNLOADER_MIDDLEWARES_BASE:分别表示自定义的下载中间件类和默认的下载中间件类;DOWNLOADER_STATS:是否启用下载器统计信息收集。
来看看 default_settings.py 中的默认配置,具体如下:
DOWNLOAD_DELAY = 0
DOWNLOAD_HANDLERS = {}
DOWNLOAD_HANDLERS_BASE = {
'data': 'scrapy.core.downloader.handlers.datauri.DataURIDownloadHandler',
'file': 'scrapy.core.downloader.handlers.file.FileDownloadHandler',
'http': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
'https': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
's3': 'scrapy.core.downloader.handlers.s3.S3DownloadHandler',
'ftp': 'scrapy.core.downloader.handlers.ftp.FTPDownloadHandler',
}
DOWNLOAD_TIMEOUT = 180 # 3mins
DOWNLOAD_MAXSIZE = 1024 * 1024 * 1024 # 1024m
DOWNLOAD_WARNSIZE = 32 * 1024 * 1024 # 32m
DOWNLOAD_FAIL_ON_DATALOSS = True
DOWNLOADER = 'scrapy.core.downloader.Downloader'
DOWNLOADER_HTTPCLIENTFACTORY = 'scrapy.core.downloader.webclient.ScrapyHTTPClientFactory'
DOWNLOADER_CLIENTCONTEXTFACTORY = 'scrapy.core.downloader.contextfactory.ScrapyClientContextFactory'
DOWNLOADER_CLIENT_TLS_CIPHERS = 'DEFAULT'
# Use highest TLS/SSL protocol version supported by the platform, also allowing negotiation:
DOWNLOADER_CLIENT_TLS_METHOD = 'TLS'
DOWNLOADER_CLIENT_TLS_VERBOSE_LOGGING = False
DOWNLOADER_MIDDLEWARES = {}
DOWNLOADER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
# Downloader side
}
DOWNLOADER_STATS = True
DUPEFILTER_CLASS:指定去重类;
DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter'
自定义扩展和内置扩展配置:
EXTENSIONS = {}
EXTENSIONS_BASE = {
'scrapy.extensions.corestats.CoreStats': 0,
'scrapy.extensions.telnet.TelnetConsole': 0,
'scrapy.extensions.memusage.MemoryUsage': 0,
'scrapy.extensions.memdebug.MemoryDebugger': 0,
'scrapy.extensions.closespider.CloseSpider': 0,
'scrapy.extensions.feedexport.FeedExporter': 0,
'scrapy.extensions.logstats.LogStats': 0,
'scrapy.extensions.spiderstate.SpiderState': 0,
'scrapy.extensions.throttle.AutoThrottle': 0,
}
文件存储相关:
FILES_STORE_S3_ACL = 'private'
FILES_STORE_GCS_ACL = ''
FTP 服务配置, Scrapy 框架内置 FTP 下载程序。我们可以指定 FTP 的相关参数:
FTP_USER = 'anonymous'
FTP_PASSWORD = 'guest'
FTP_PASSIVE_MODE = True
HTTP 缓存相关配置。Scrapy 的 HttpCacheMiddleware 组件(默认情况下没有启用)提供了一个底层的对HTTP请求和响应的缓存。如果启用的话(把HTTPCACHE_ENABLED设置为True),它会缓存每个请求和对应的响应。来看看和其相关的配置和含义:
# 是否启用http缓存
HTTPCACHE_ENABLED = False
# 缓存数据目录
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_MISSING = False
# 缓存存储的插件
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 缓存过期时间
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_ALWAYS_STORE = False
# 缓存忽略的Http状态码
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_IGNORE_SCHEMES = ['file']
HTTPCACHE_IGNORE_RESPONSE_CACHE_CONTROLS = []
HTTPCACHE_DBM_MODULE = 'dbm'
# 设置缓存策略,DummyPolicy是所有请求均缓存,下次在请求直接访问原来的缓存即可
HTTPCACHE_POLICY = 'scrapy.extensions.httpcache.DummyPolicy'
# 是否启用缓存数据压缩
HTTPCACHE_GZIP = False
Item 和 Item pipelines相关配置:
# ITEM处理器
ITEM_PROCESSOR = 'scrapy.pipelines.ItemPipelineManager'
# 自定义的 item pipelines
ITEM_PIPELINES = {}
ITEM_PIPELINES_BASE = {}
日志相关的配置:
# 启动日志功能
LOG_ENABLED = True
# 日志编码
LOG_ENCODING = 'utf-8'
# 日志格式器
LOG_FORMATTER = 'scrapy.logformatter.LogFormatter'
# 日志格式
LOG_FORMAT = '%(asctime)s [%(name)s] %(levelname)s: %(message)s'
# 日志时间格式
LOG_DATEFORMAT = '%Y-%m-%d %H:%M:%S'
LOG_STDOUT = False
# 日志级别
LOG_LEVEL = 'DEBUG'
# 指定日志输出文件
LOG_FILE = None
LOG_SHORT_NAMES = False
邮件配置:在 Scrapy 中提供了邮件功能,该功能使用十分简便且采用了 Twisted 非阻塞模式,避免了对爬虫的影响。我们只需要在 Scrapy 中进行简单的设置,就能通过 API 发送邮件。邮件的默认配置项如下:
MAIL_HOST = 'localhost'
MAIL_PORT = 25
MAIL_FROM = 'scrapy@localhost'
MAIL_PASS = None
MAIL_USER = None
我们现在可以简单的使用下 Scrapy 给我们提供的邮件类,来利用它给我们自己发送一封邮件。首先需要找下自己的 qq 邮箱或者其他邮箱,开启 POP3/SMTP服务,然后我们可以得到一个授权码。这个就是我们登陆这个邮箱服务的密码。然后我们配置 settings.py 中的相应项:
MAIL_HOST = 'smtp.qq.com'
MAIL_PORT = 25
MAIL_FROM = '2894577759@qq.com'
MAIL_PASS = '你的授权码'
MAIL_USER = '2894577759@qq.com'
接下来我们在 scrapy shell 中来调用相应的邮件接口,发送邮件:
(scrapy-test) [root@server china_pub]# scrapy shell --nolog
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x7f1c3d4e9100>
[s] item {}
[s] settings <scrapy.settings.Settings object at 0x7f1c3d4e6dc0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>> from scrapy.mail import MailSender
>>> mailer = MailSender().from_settings(settings)
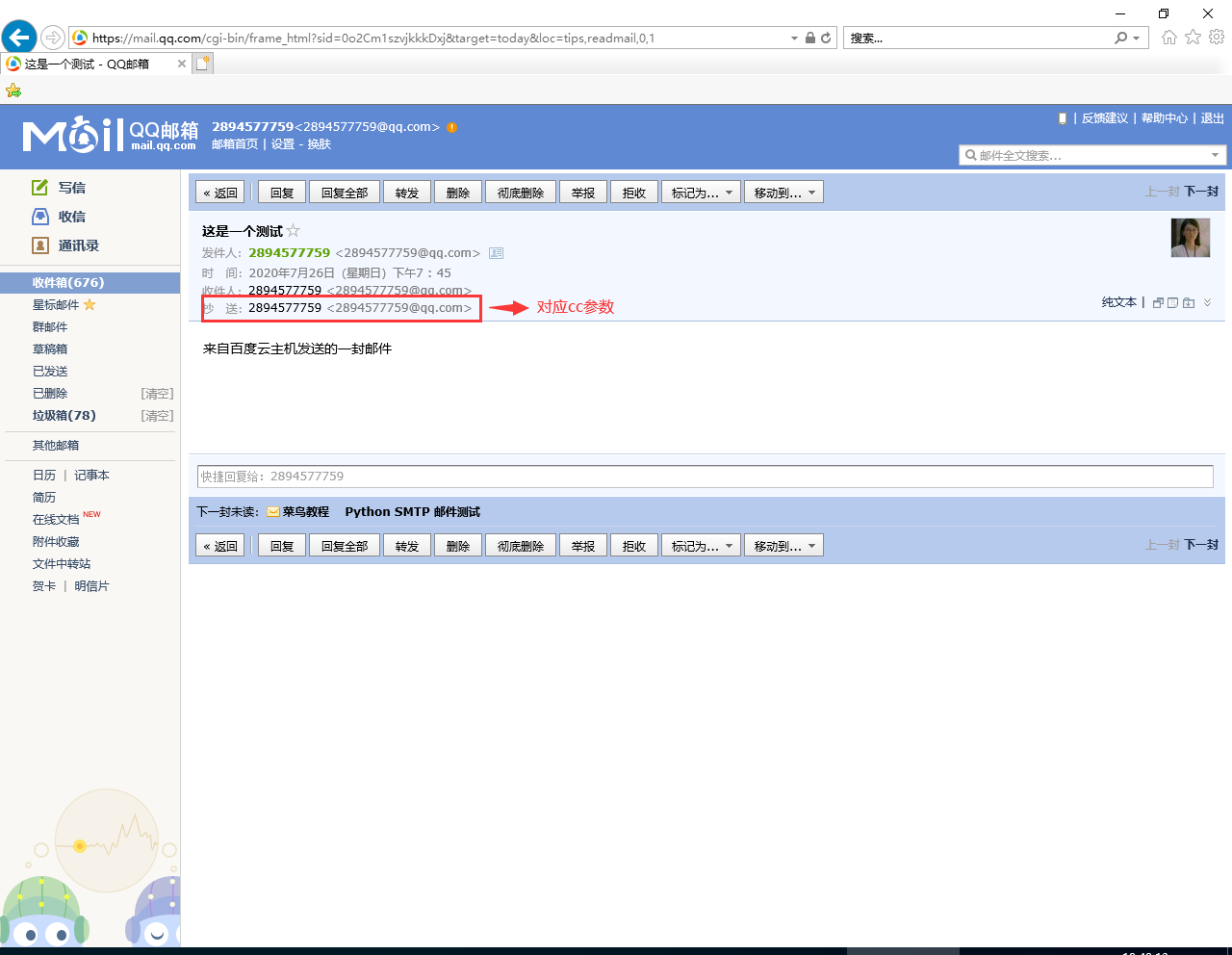
>>> mailer.send(to=["2894577759@qq.com"], subject="这是一个测试", body="来自百度云主机发送的一封邮件", cc=["2894577759@qq.com"])
<Deferred at 0x7f1c3c4d1c40>
内存相关参数:
MEMDEBUG_ENABLED = False # enable memory debugging
MEMDEBUG_NOTIFY = [] # send memory debugging report by mail at engine shutdown
MEMUSAGE_CHECK_INTERVAL_SECONDS = 60.0
# 是否启用内存使用扩展
MEMUSAGE_ENABLED = True
# 在关闭Scrapy之前允许的最大内存量,为0则不检查
MEMUSAGE_LIMIT_MB = 0
# 要达到内存限制时通知的电子邮件列表
MEMUSAGE_NOTIFY_MAIL = []
# 在发送警告电子邮件通知之前,要允许的最大内存量(以兆字节为单位)。如果为零,则不会产生警告
MEMUSAGE_WARNING_MB = 0
调度器相关配置:
# 调度器类
SCHEDULER = 'scrapy.core.scheduler.Scheduler'
# 指定调度器的三种队列类
SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleLifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.LifoMemoryQueue'
SCHEDULER_PRIORITY_QUEUE = 'scrapy.pqueues.ScrapyPriorityQueue'
# 正在处理响应数据的软限制(以字节为单位),如果所有正在处理的响应的大小总和高于此值,Scrapy不会处理新的请求
SCRAPER_SLOT_MAX_ACTIVE_SIZE = 5000000
spider 中间件相关配置,有我们熟悉的 SPIDER_MIDDLEWARES 和 SPIDER_MIDDLEWARES_BASE,表示自定义的 Spider 中间件和 Scrapy 内置的 Spider 中间件;
SPIDER_MIDDLEWARES = {}
SPIDER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800,
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
# Spider side
}
指定模板文件目录,这个在使用 scrapy startproject 项目名 命令创建项目时,对应的模板文件所在的目录:
TEMPLATES_DIR = abspath(join(dirname(__file__), '..', 'templates'))
USER_AGENT:设置请求头的 User-Agent 参数,用来模拟浏览器。我们通常都会添加一个浏览器的 User-Agent 值,防止爬虫直接被屏蔽;
Scrapy 的大体配置就是这些,还有一些没有介绍到的参数,课后可以仔细查看官方文档进行了解。
2. 常见的优化配置参数
首先 scrapy 框架有一个命令 (bench) 来帮助我们测试本地环境的效率,它会在本地创建一个 HTTP 服务器,并以最大可能的速度进行爬取,这个模拟的 Spider 只会做跟进连接操作,而不做其他处理。我们来实际看看这个命令的执行效果:
(scrapy-test) [root@server qidian_yuepiao]# scrapy bench
# ...
2020-07-25 23:35:07 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 127918,
'downloader/request_count': 278,
'downloader/request_method_count/GET': 278,
'downloader/response_bytes': 666962,
'downloader/response_count': 278,
'downloader/response_status_count/200': 278,
'elapsed_time_seconds': 11.300798,
'finish_reason': 'closespider_timeout',
'finish_time': datetime.datetime(2020, 7, 25, 15, 35, 7, 370135),
'log_count/INFO': 21,
'memusage/max': 48553984,
'memusage/startup': 48553984,
'request_depth_max': 12,
'response_received_count': 278,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/200': 1,
'scheduler/dequeued': 277,
'scheduler/dequeued/memory': 277,
'scheduler/enqueued': 5540,
'scheduler/enqueued/memory': 5540,
'start_time': datetime.datetime(2020, 7, 25, 15, 34, 56, 69337)}
2020-07-25 23:35:07 [scrapy.core.engine] INFO: Spider closed (closespider_timeout)
在上面的执行日志中,我们可以很清楚的看到该命令会搜索 settings.py 中的配置并打印项目的基本信息以及启用的扩展、下载中间件、Spider 中间件以及相应的 item pipelines。接下来是做的一些本地环境测试,测试显示的是每分钟平均能抓取1440个页面,当然实际的爬虫程序中需要有较多的处理,比如抽取页面数据、过滤、去重以及保存到数据库中,这些都是会消耗一定时间的。
现在来介绍一下 settings.py 中比较常见的一个优化配置:
-
并发控制:settings.py 中的
CONCURRENT_REQUESTS参数用来确定请求的并发数,默认给的是16。而这个参数往往不适用于本地环境,我们需要进行调整。调整的方法是一开始设置一个比较大的值,比如100,然后进行测试,得到 Scrapy 的并发请求数与 CPU 使用率之间的关系,我们选择大概使得 CPU 使用率在 80%~90% 对应的并发数,这样能使得 Scrapy 爬虫充分利用 CPU 进行网页爬取; -
关闭 Cookie :这也是一个常见的优化策略。对于一些网站的请求,比如起点网、京东商城等, 不用登录都可以任意访问数据的,没有必要使用 Cookie,使用 Cookie 而会增加 Scrapy 爬虫的工作量。直接设置
COOKIES_ENABLED = False即可关闭 Cookie; -
设置 Log 级别:将默认的 DEBUG 级别调整至 INFO 级别,减少不必要的日志打印;
-
关闭重试:默认情况下 Scrapy 会对失败的请求进行重试,这种操作会减慢数据的爬取效率,因为对于海量的请求而言,丢失的数个甚至数百个请求都无关紧要;反而不必要的尝试会影响爬虫爬取效率;生产环境的做法最好是直接关闭,即
RETRY_ENABLED = False; -
减少下载超时时间:对于响应很慢的网站,在超时时间结束前,Scrapy 会持续等到响应返回,这样容易造成资源浪费。因此一个常见的优化策略是,减少超时时间,尽量让响应慢的请求释放资源。相应的参数设置示例如下:
DOWNLOAD_TIMEOUT = 3 -
关闭重定向:除非对重定向内容感兴趣,否则可以考虑关闭重定向。关闭操作
REDIRECT_ENABLED = False; -
自动调整爬虫负载:我们启用这个可以自动调节服务器负载的扩展程序,设置相关的参数,可以一定程度上优化爬虫的性能;
AUTOTHROTTLE_ENABLED = False # 默认不启用,可以设置为True并调整下面相关参数 AUTOTHROTTLE_DEBUG = False AUTOTHROTTLE_MAX_DELAY = 60.0 AUTOTHROTTLE_START_DELAY = 5.0 AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
3. 小结
本小节中我们首先介绍了 settings.py 中的相关配置参数,先了解这些基础的配置的含义,然后才知道如何选择较合适的参数,这些对于 Scrapy 爬虫性能有着较大的影响。当然这些性能变化可能在我们编写的实验性爬虫中无法体现,但是对于真正的爬虫公司而言,这些参数的调优对他们而言至关重要,甚至能决定公司的核心竞争力。为此,我们需要积极储备相关知识,说不定会在未来有一天用的上。
- 还没有人评论,欢迎说说您的想法!
 客服
客服


