


深入分析 Scrapy 下载器原理
今天我们来完整分析下 Scrapy 中下载器模块的代码,深入理解下载器的实现原理以及用到的 Twisted 相关模块。本节的内容会有些枯燥,请耐心阅读下去。
1. Twisted 中的 Web Client 模块
本小节内容主要参考官方文档对于 Web Client 模块的介绍,也就是文献1。这部分内容正是 Scrapy 下载器的核心,为了能更好的理解下载器,我们需要先学习下 Twisted 中的这块内容。
1.1 发出请求
注意 twisted.web.client.Agent 这个类,它是客户端 API 的入口点,请求是使用 request() 方法发出的,该方法以请求方法、请求URI、请求头和可以生成请求体的对象作为参数。代理负责连接设置。因此,它需要一个 reactor 作为初始值设定项的参数。来看官方给的第一个简单例子:
from __future__ import print_function
from twisted.internet import reactor
from twisted.web.client import Agent
from twisted.web.http_headers import Headers
agent = Agent(reactor)
d = agent.request(
b'GET',
b'http://www.imooc.com/wiki/',
Headers({'User-Agent': ['Twisted Web Client Example']}),
None)
def cbResponse(ignored):
print('Response received')
d.addCallback(cbResponse)
# 关闭reactor()
def cbShutdown(ignored):
reactor.stop()
d.addBoth(cbShutdown)
reactor.run()
上述代码简单实例化一个 agent,然后调用 request() 方法请求 http://www.imooc.com/wiki/ 这个地址,这个动作也是一个延迟加载的方式;接下来的回调链中还会有请求完成后打印收到响应的方法以及最后关闭 reactor 的方法;执行的结果如下:
[root@server2 scrapy-test]# python3 request.py
Response received
如果想要给请求带上参数,就需要传递一个 twisted.web.iweb.IBodyProducer 类型的对象到 Agent.request。我们继续来学习官方给出的第二个例子:
下面的代码给出了一个简单的 IBodyProducer 实现,它向使用者写入内存中的字符串
# 代码文件命名为:bytesprod.py
from zope.interface import implementer
from twisted.internet.defer import succeed
from twisted.web.iweb import IBodyProducer
@implementer(IBodyProducer)
class BytesProducer(object):
def __init__(self, body):
self.body = body
self.length = len(body)
def startProducing(self, consumer):
consumer.write(self.body)
return succeed(None)
def pauseProducing(self):
pass
def stopProducing(self):
pass
下面的代码则在请求中带上了 body 体:
# 代码文件:sendbody.py
from twisted.internet import reactor
from twisted.web.client import Agent
from twisted.web.http_headers import Headers
from bytesprod import BytesProducer
agent = Agent(reactor)
# 构造请求体
body = BytesProducer(b"hello, world")
d = agent.request(
b'POST',
b'http://httpbin.org/post',
Headers({'User-Agent': ['Twisted Web Client Example'],
'Content-Type': ['text/x-greeting']}),
# 带上body
body)
# 回调链,收到上个request的请求响应
def cbResponse(ignored):
print('Response received')
d.addCallback(cbResponse)
# 关闭reactor
def cbShutdown(ignored):
reactor.stop()
d.addBoth(cbShutdown)
reactor.run()
1.2 接收响应
接下来一个内容就是关于数据的接收。前面的代码都只有请求,没有接收响应数据。如果 Agent.request 请求成功,则 Deferred 将触发一个响应。一旦收到所有响应头,就会发生这种情况。它发生在处理任何响应体 (如果有)之前。Response 对象有一个使响应体可用的方法:deliverBody,接下来我们给出一个使用实例:
from __future__ import print_function
from pprint import pformat
from twisted.internet import reactor
from twisted.internet.defer import Deferred
from twisted.internet.protocol import Protocol
from twisted.web.client import Agent
from twisted.web.http_headers import Headers
# 继承Protocol
class BeginningPrinter(Protocol):
def __init__(self, finished):
self.finished = finished
self.remaining = 1024 * 10
def dataReceived(self, bytes):
"""
响应的数据从该方法获取,最终获取的数据大小不超过self.remaining
"""
if self.remaining:
display = bytes[:self.remaining]
print('Some data received:')
print(str(display, encoding='utf8'))
self.remaining -= len(display)
def connectionLost(self, reason):
print('Finished receiving body:', reason.getErrorMessage())
self.finished.callback(None)
# 获取agent实例,传入reactor
agent = Agent(reactor)
# 请求慕课网wiki
d = agent.request(
b'GET',
b'http://www.imooc.com/wiki/',
Headers({'User-Agent': ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36']}),
None)
def cbRequest(response):
finished = Deferred()
# 获取响应数据
response.deliverBody(BeginningPrinter(finished))
return finished
# 加入回调链
d.addCallback(cbRequest)
def cbShutdown(ignored):
reactor.stop()
d.addBoth(cbShutdown)
reactor.run()
我们可以直接来看看这个:
其实仔细分析 Scrapy 下载器源码我们可以在 scrapy/core/downloader/handlers/http11.py 的代码中看到如下非常类似的代码:
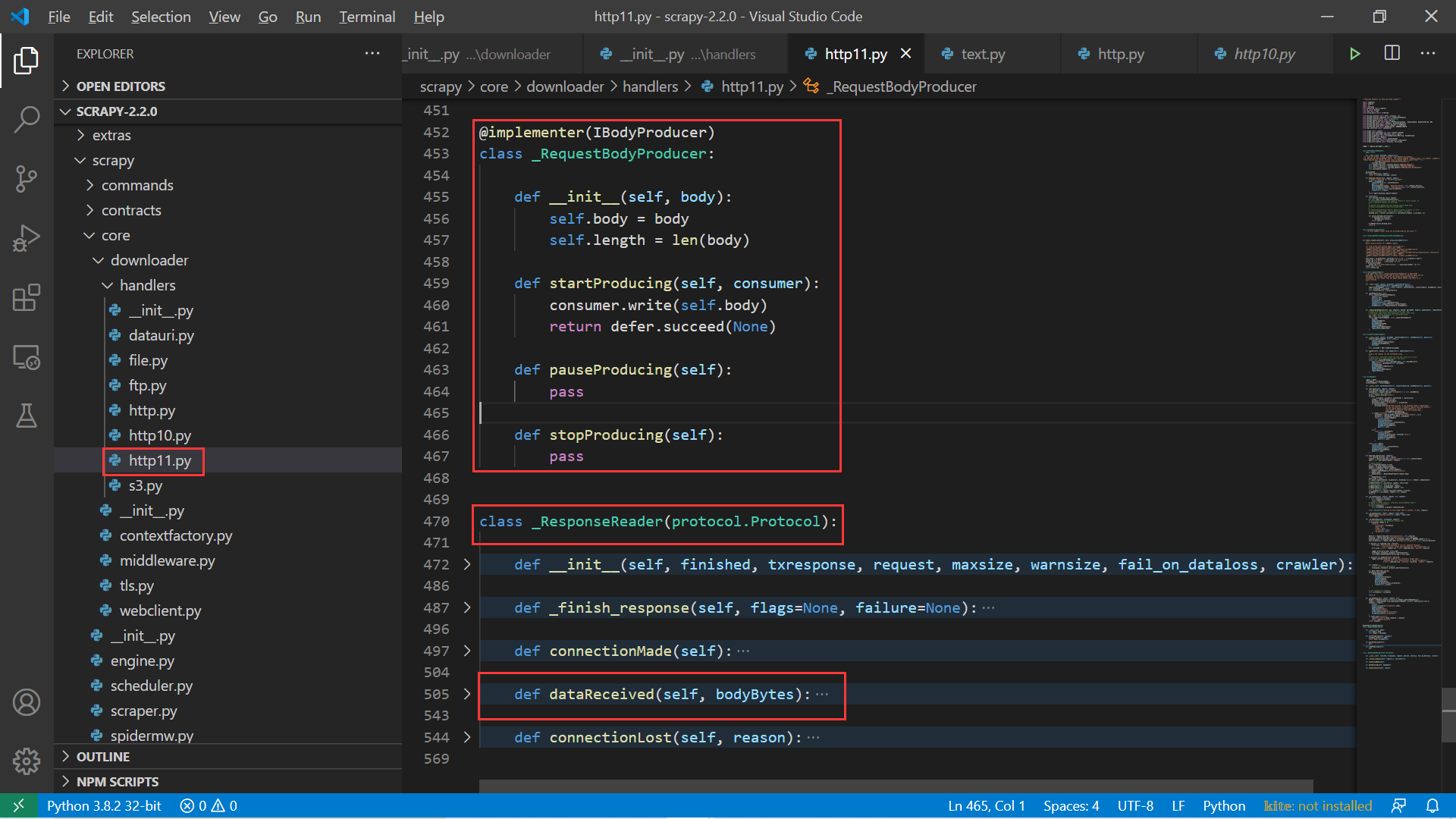
2. Scrapy 中下载器模块源码分析
2.1 下载器的__init__() 方法分析
我们直接看源码目录,关于下载器模块的代码全在 scrapy/core/downloader 目录下:
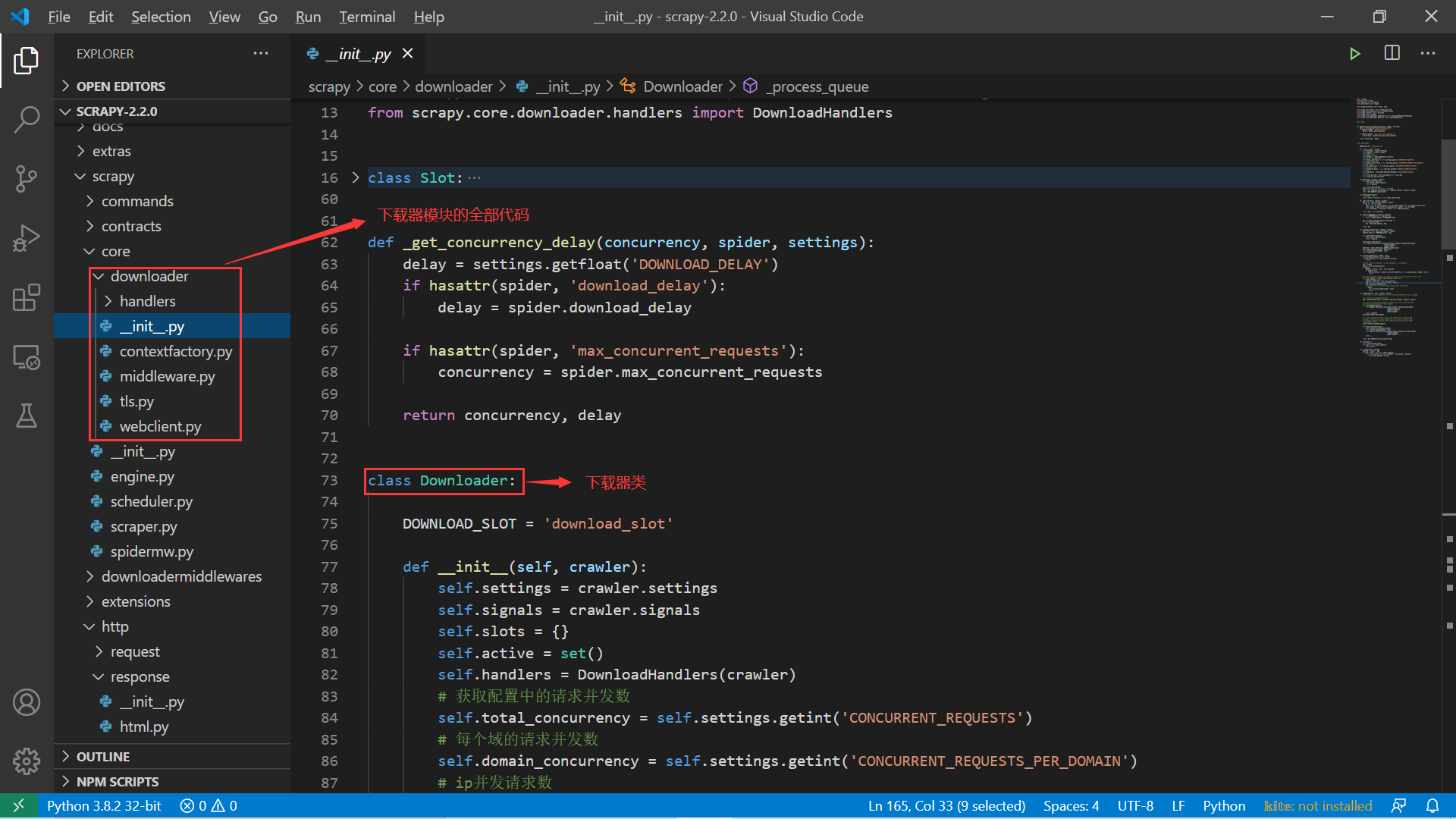
其中主要的核心代码就是这个 __init__.py 文件,其中定义了 Downloader 这个类,它就是我们的下载器。首先来看这个类的初始化过程:
# ...
class Downloader:
DOWNLOAD_SLOT = 'download_slot'
def __init__(self, crawler):
# 获取配置
self.settings = crawler.settings
self.signals = crawler.signals
self.slots = {}
self.active = set()
# 获取handlers
self.handlers = DownloadHandlers(crawler)
# 获取配置中的请求并发数
self.total_concurrency = self.settings.getint('CONCURRENT_REQUESTS')
# 每个域的请求并发数
self.domain_concurrency = self.settings.getint('CONCURRENT_REQUESTS_PER_DOMAIN')
# ip并发请求数
self.ip_concurrency = self.settings.getint('CONCURRENT_REQUESTS_PER_IP')
# 是否设置随机延迟
self.randomize_delay = self.settings.getbool('RANDOMIZE_DOWNLOAD_DELAY')
# 中间件管理器
self.middleware = DownloaderMiddlewareManager.from_crawler(crawler)
self._slot_gc_loop = task.LoopingCall(self._slot_gc)
self._slot_gc_loop.start(60)
从这个初始化的过程中,我们要重点关注几个属性值:
-
settings:对应的 scrapy 项目配置;
-
handlers:实例化 DownloadHandlers, 而这个类则是网页下载的最终处理类;
-
各种配置属性:从 settings.py 中获取控制并发的参数;
-
middleware:下载中间件的管理器,在下一节中我们会详细分析这个属性;
2.2 下载器实例的 handlers 属性值分析
重点先看看这个 handlers 属性值,它是 DownloadHandlers 类的一个实例,对应的代码位置为:scrapy/core/downloader/handlers/__init__.py 。其类定义如下:
# ...
class DownloadHandlers:
def __init__(self, crawler):
self._crawler = crawler
self._schemes = {} # stores acceptable schemes on instancing
self._handlers = {} # stores instanced handlers for schemes
self._notconfigured = {} # remembers failed handlers
handlers = without_none_values(
crawler.settings.getwithbase('DOWNLOAD_HANDLERS'))
for scheme, clspath in handlers.items():
self._schemes[scheme] = clspath
self._load_handler(scheme, skip_lazy=True)
crawler.signals.connect(self._close, signals.engine_stopped)
def _get_handler(self, scheme):
"""Lazy-load the downloadhandler for a scheme
only on the first request for that scheme.
"""
if scheme in self._handlers:
return self._handlers[scheme]
if scheme in self._notconfigured:
return None
if scheme not in self._schemes:
self._notconfigured[scheme] = 'no handler available for that scheme'
return None
return self._load_handler(scheme)
def _load_handler(self, scheme, skip_lazy=False):
path = self._schemes[scheme]
try:
dhcls = load_object(path)
if skip_lazy and getattr(dhcls, 'lazy', True):
return None
dh = create_instance(
objcls=dhcls,
settings=self._crawler.settings,
crawler=self._crawler,
)
except NotConfigured as ex:
self._notconfigured[scheme] = str(ex)
return None
except Exception as ex:
# ...
else:
self._handlers[scheme] = dh
return dh
def download_request(self, request, spider):
scheme = urlparse_cached(request).scheme
handler = self._get_handler(scheme)
if not handler:
raise NotSupported("Unsupported URL scheme '%s': %s" %
(scheme, self._notconfigured[scheme]))
return handler.download_request(request, spider)
@defer.inlineCallbacks
def _close(self, *_a, **_kw):
# ...
我们分别来解析这个类中定义的方法,都是非常重要的。此外,每个方法含义明确,而且代码精炼,我们对此一一进行说明。
首先是 __init__() 方法,我们可以看到一个核心的语句:handlers = without_none_values(crawler.settings.getwithbase('DOWNLOAD_HANDLERS'))。其中 getwithbase() 方法的定义位于 scapy/settings/__init__.py 文件中,其内容如下:
# 源码位置:scrapy/settings/__init__.py
# ...
class BaseSettings(MutableMapping):
# ...
def getwithbase(self, name):
"""Get a composition of a dictionary-like setting and its `_BASE`
counterpart.
:param name: name of the dictionary-like setting
:type name: string
"""
compbs = BaseSettings()
compbs.update(self[name + '_BASE'])
compbs.update(self[name])
return compbs
# ...
从上面的代码中,可以知道 crawler.settings.getwithbase('DOWNLOAD_HANDLERS') 语句其实是获取了 settings.py 配置中的 DOWNLOAD_HANDLERS 和 DOWNLOAD_HANDLERS_BASE 值,并返回包含这两个属性值的 BaseSettings 实例。我们从默认的 scrapy/settings/default_settings.py 中可以看到这两个属性值如下:
# 源码位置:scrapy/settings/default_settings.py
DOWNLOAD_HANDLERS = {}
DOWNLOAD_HANDLERS_BASE = {
'data': 'scrapy.core.downloader.handlers.datauri.DataURIDownloadHandler',
'file': 'scrapy.core.downloader.handlers.file.FileDownloadHandler',
'http': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
'https': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
's3': 'scrapy.core.downloader.handlers.s3.S3DownloadHandler',
'ftp': 'scrapy.core.downloader.handlers.ftp.FTPDownloadHandler',
}
通常我们项目中的下载请求一般是 http 或者 https,对应的都是 scrapy.core.downloader.handlers.http.HTTPDownloadHandler 这个位置的 handler,从这里也可以看到 scrapy 框架其实是支持非常多协议下载的,比如 s3 下载、文件下载以及 ftp下载等。紧接着的两句就是在设置 self._schemes 和 self._handlers 的值。其中 self._handlers 会加载对应 Handler 类:
def _load_handler(self, scheme, skip_lazy=False):
# 获取协议对应的handler类路径,比如 ftp协议对应着的handler类为
# scrapy.core.downloader.handlers.ftp.FTPDownloadHandler
path = self._schemes[scheme]
try:
# 获取相应的handler类,非字符串形式
dhcls = load_object(path)
# 默认__init__()方法调用时参数skip_lazy为True,我们需要检查对应handler类中的lazy属性值,没有设置时默认为True;如果handler类中lazy属性设置为True或者不设置,则该handler不会加入到self._handlers中
if skip_lazy and getattr(dhcls, 'lazy', True):
return None
# 创建相应的handler类实例,需要的参数为:
dh = create_instance(
objcls=dhcls,
settings=self._crawler.settings,
crawler=self._crawler,
)
except NotConfigured as ex:
# ...
except Exception as ex:
# ...
else:
# 设置self._handlers
self._handlers[scheme] = dh
return dh
上面的注释已经非常清楚,在众多 handlers 中,只有 S3DownloadHandler 类中没有设置 lazy。所以在 __init__() 方法执行完后,self._handlers 中不会有键 “s3” 及其对应的实例。
_get_handler() 就非常明显了,由于我们在初始化方法 __init__() 中已经得到了 self._handlers,此时该方法就是根据传入的协议获取相应 Handler 类的实例。 例如传入的 scheme="http",则返回就是 HTTPDownloadHandler 类的一个实例。
最后一个 download_request() 方法可以说是下载网页的核心调用方法。我们来逐步分析该方法中的语句:
scheme = urlparse_cached(request).scheme
handler = self._get_handler(scheme)
上面两句是获取对应的下载请求的 Handler 实例,比较容易理解。接下来的 return 就是调用 handler 实例中的 download_request() 方法按照对应协议方式下载请求数据:
return handler.download_request(request, spider)
每个 handler 类都会有对应的 download_request() 方法。我们重点看看 http 和 https 协议对应的 handler 类:
# 源码位置:scrapy/core/downloader/handlers/http.py
from scrapy.core.downloader.handlers.http10 import HTTP10DownloadHandler
from scrapy.core.downloader.handlers.http11 import (
HTTP11DownloadHandler as HTTPDownloadHandler,
)
可以看到,这里的 HTTPDownloadHandler 类实际上是 http11.py 中的 HTTP11DownloadHandler 类。这里面内容有点多,我们简要地分析下:
# 源码位置:scrapy/core/downloader/handlers/http11.py
# ...
class HTTP11DownloadHandler:
# ...
def download_request(self, request, spider):
"""Return a deferred for the HTTP download"""
agent = ScrapyAgent(
contextFactory=self._contextFactory,
pool=self._pool,
maxsize=getattr(spider, 'download_maxsize', self._default_maxsize),
warnsize=getattr(spider, 'download_warnsize', self._default_warnsize),
fail_on_dataloss=self._fail_on_dataloss,
crawler=self._crawler,
)
return agent.download_request(request)
# ...
是不是挺简单的两条语句:得到 agent,然后调用 agent.download_request() 方法得到请求的结果?我们继续追踪这个 ScrapyAgent 类:
# 源码位置:scrapy/core/downloader/handlers/http11.py
# ...
from twisted.web.client import Agent, HTTPConnectionPool, ResponseDone, ResponseFailed, URI
# ...
class ScrapyAgent:
_Agent = Agent
# ...
def _get_agent(self, request, timeout):
from twisted.internet import reactor
bindaddress = request.meta.get('bindaddress') or self._bindAddress
# 从请求的meta参数中获取proxy
proxy = request.meta.get('proxy')
if proxy:
# 有代理的情况
# ...
# 没有代理返回Agent的一个实例
return self._Agent(
reactor=reactor,
contextFactory=self._contextFactory,
connectTimeout=timeout,
bindAddress=bindaddress,
pool=self._pool,
)
def download_request(self, request):
from twisted.internet import reactor
# 从meta中获取下载超时时间
timeout = request.meta.get('download_timeout') or self._connectTimeout
# 获取agent
agent = self._get_agent(request, timeout)
# request details
url = urldefrag(request.url)[0]
method = to_bytes(request.method)
headers = TxHeaders(request.headers)
if isinstance(agent, self._TunnelingAgent):
headers.removeHeader(b'Proxy-Authorization')
if request.body:
bodyproducer = _RequestBodyProducer(request.body)
else:
bodyproducer = None
start_time = time()
# 使用agent发起请求
d = agent.request(method, to_bytes(url, encoding='ascii'), headers, bodyproducer)
# set download latency
d.addCallback(self._cb_latency, request, start_time)
# response body is ready to be consumed
d.addCallback(self._cb_bodyready, request)
d.addCallback(self._cb_bodydone, request, url)
# check download timeout
self._timeout_cl = reactor.callLater(timeout, d.cancel)
d.addBoth(self._cb_timeout, request, url, timeout)
return d
看完上面的代码就应该比较清楚了,我们先不考虑代理的相关代码。直接看 _get_agent() 方法就是获取 twisted 模块中 Agent 的一个实例,然后通过这个 agent 去请求网页 (在 download_request() 方法中完成 ),最后返回的仍然是一个 Deferred 对象。在 download_request() 中的代码就和我们在第一小节中介绍的类似,这里便是 Scrapy 最后完成网页抓取的地方,就是基于 Twisted 的 web client 部分的方法。其中,最核心的一行语句就是:
d = agent.request(method, to_bytes(url, encoding='ascii'), headers, bodyproducer)
这个分析已经走到了 Scrapy 下载器的最后一层,在往下就是研究 Twisted 框架的源码了。同学们有兴趣的话,可以继续追踪下去,对本节课而言,追踪到此已经结束了。我们跳出 handlers,继续研究 Downloader 类。
2.3 下载器的 _download() 分析
我们回到 Downloader 类上继续学习,该下载器类中最核心的有如下三个方法:
_enqueue_request():请求入队;_process_queue():处理队列中的请求;_download():下载网页;
从代码中很明显可以看到,三个函数的关系如下:

Downloader中三个核心函数关系
我们来重点看看这个 _download() 方法:
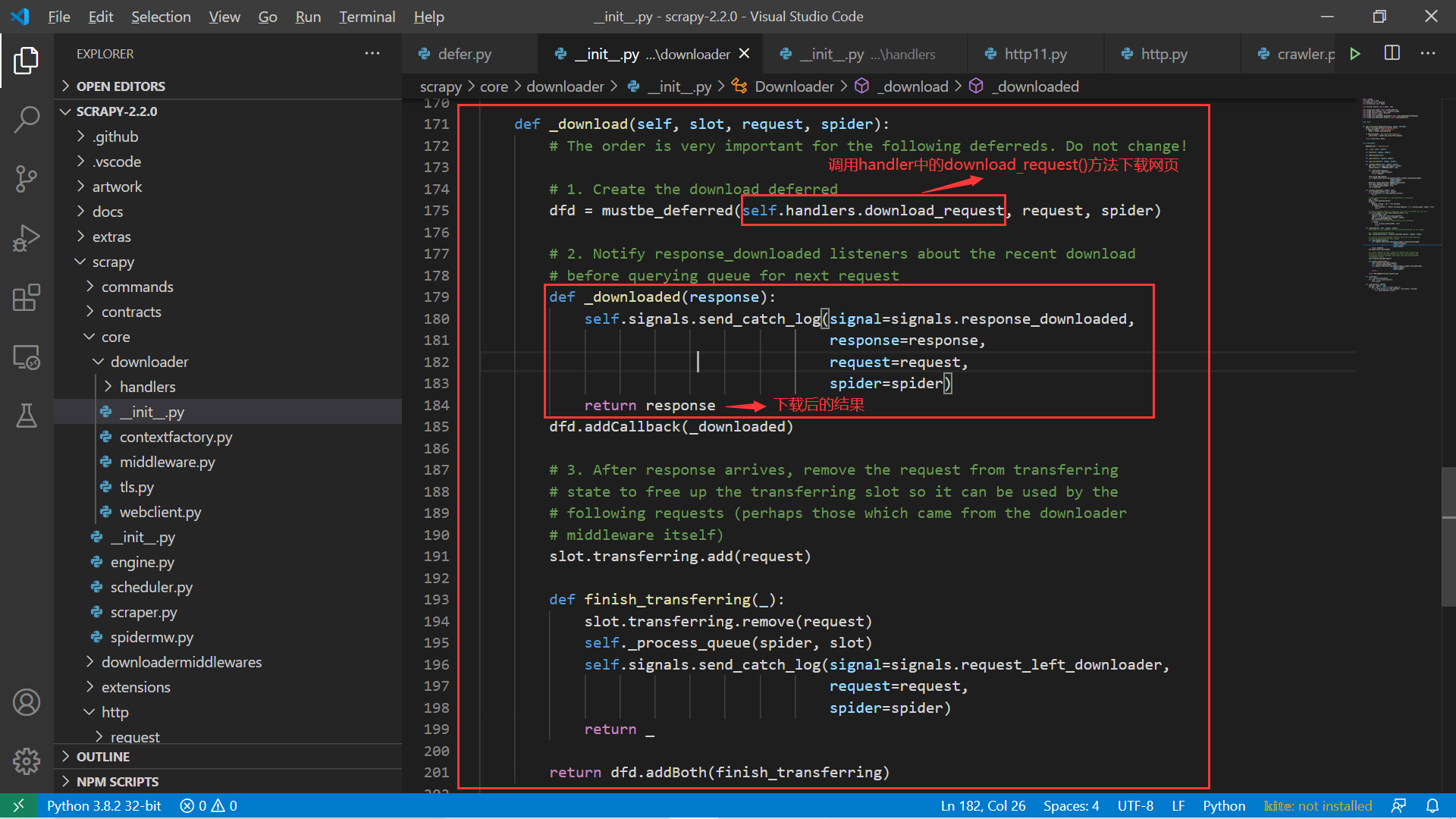
_download()方法分析
看图中注释部分,_download() 方法先创建一个下载的 deferred,注意这里的方法正是 self.handlers 的 download_request() 方法,这是网页下载的主要语句。 接下来又使用 deferred 的 addCallback() 方法添加一个回调函数:_downloaded()。很明显,_downloaded() 就是下载完成后调用的方法,其中 response 就是下载的结果,也就是后续会返回给 spider 中的 parse() 方法的那个。我们可以简单做个实验,看看是不是真的会在这里打印出响应的结果:
创建一个名为 test_downloader 的 scrapy 的项目:
[root@server2 scrapy-test]# scrapy startproject test_downloader
生成一个名为 downloader 的 spider:
# 进入到spider目录
[root@server2 scrapy-test]# cd test_downloader/test_downloader/spiders/
# 新建一个spider文件
[root@server2 spiders]# scrapy genspider downloader www.imooc.com/wiki/
[root@server2 spiders]# cat downloader.py
import scrapy
class DownloaderSpider(scrapy.Spider):
name = 'downloader'
allowed_domains = ['www.imooc.com/wiki/']
start_urls = ['http://www.imooc.com/wiki/']
def parse(self, response):
pass
我们添加几个配置,将 scrapy 的日志打到文件中,避免影响我们打印一些结果:
# test_download/settings.py
# ...
#是否启动日志记录,默认True
LOG_ENABLED = True
LOG_ENCODING = 'UTF-8'
#日志输出文件,如果为NONE,就打印到控制台
LOG_FILE = 'downloader.log'
#日志级别,默认DEBUG
LOG_LEVEL = 'INFO'
# 日志日期格式
LOG_DATEFORMAT = "%Y-%m-%d %H:%M:%S"
#日志标准输出,默认False,如果True所有标准输出都将写入日志中,比如代码中的print输出也会被写入到
LOG_STDOUT = False
最重要的步骤来啦,我们在 scrapy 的源码 scrapy/core/downloader/__init__.py 的中添加一些代码,用于查看下载器获取的结果:
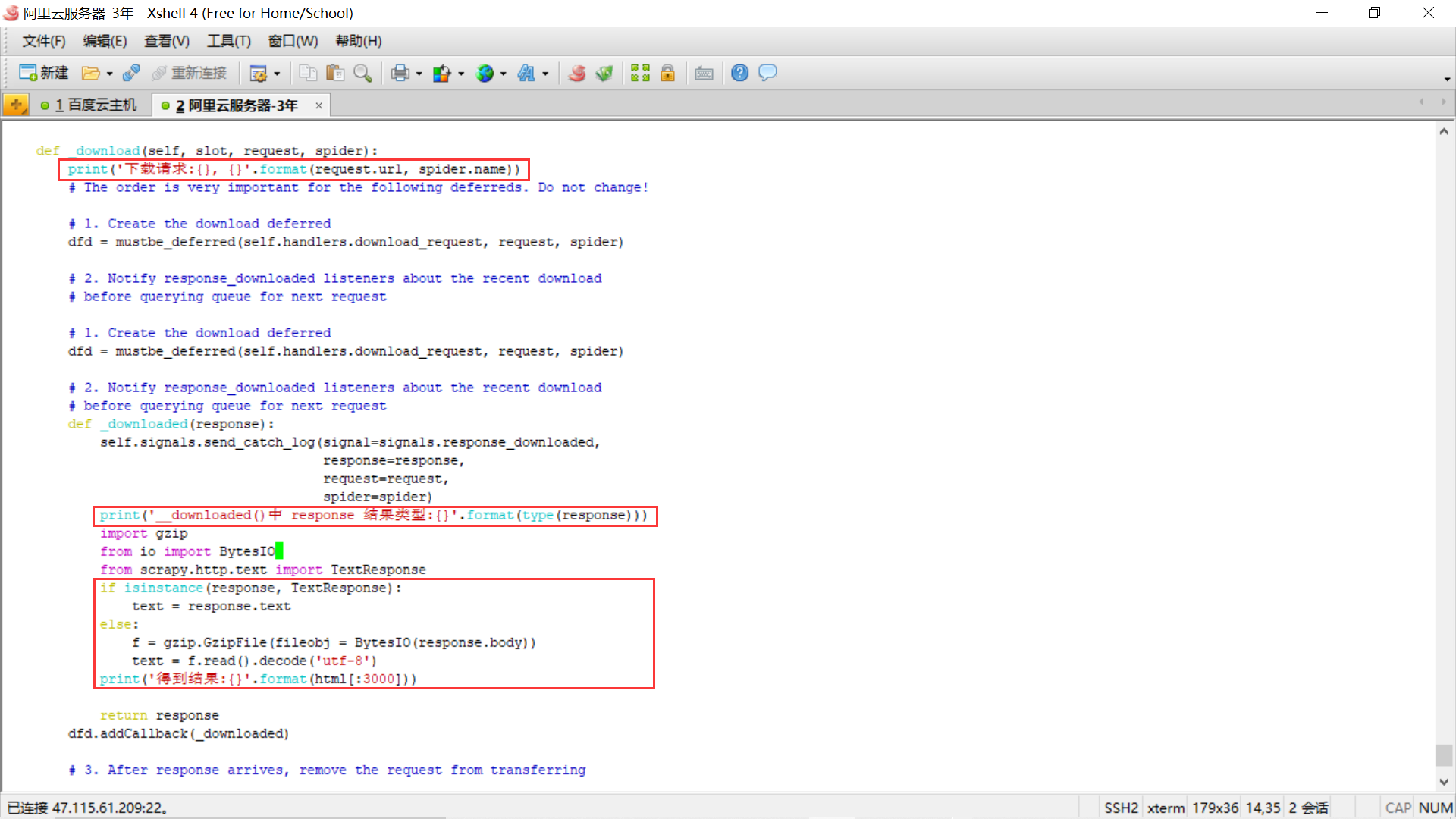
我们来对添加的这部分代码进行下说明:
# ...
class Downloader:
# ...
def _download(self, slot, request, spider):
print('下载请求:{}, {}'.format(request.url, spider.name))
# The order is very important for the following deferreds. Do not change!
# 1. Create the download deferred
dfd = mustbe_deferred(self.handlers.download_request, request, spider)
# 2. Notify response_downloaded listeners about the recent download
# before querying queue for next request
def _downloaded(response):
self.signals.send_catch_log(signal=signals.response_downloaded,
response=response,
request=request,
spider=spider)
###############################新增代码########################################
print('__downloaded()中 response 结果类型:{}'.format(type(response)))
import gzip
from io import BytesIO
from scrapy.http.response.text import TextResponse
if isinstance(response, TextResponse):
text = response.text
else:
# 解压缩文本,这部分会在后续的下载中间件中被处理,传给parse()方法时会变成解压后的数据
f = gzip.GzipFile(fileobj = BytesIO(response.body))
text = f.read().decode('utf-8')
print('得到结果:{}'.format(text[:3000]))
############################################################################
return response
但就我们新建的项目而言,只是简单的爬取慕课网的 wiki 页面,获取相应的页面数据。由于我们没有禁止 robot 协议,所以项目第一次会爬取 /robots.txt 地址,检查 wiki 页面是否允许爬取;接下来才会爬取 wiki 页面。测试发现,第一次请求 /robots.txt 地址时,在 _downloaded() 中得到的结果直接就是 TextResponse 实例,我们可以用 response.text 方式直接拿到结果;但是第二次请求 http://www.imooc.com/wiki/ 时,返回的结果是经过压缩的,其结果的前三个字节码为:b'x1fx8bx08' 开头的 ,说明它是 gzip 压缩过的数据。为了能查看相应的数据,我们可以在这里解码查看,对应的就是上面的 else 部分代码。我们现在来进行演示:
3. 小结
本小节中我们详尽的剖析了 Scrapy 的下载器模块,找出了最终请求网页数据的方式。整个下载器的代码不算特别复杂,主要是对 Twisted 的 web client 模块中的类和方法的进一步封装,我们可以通过参考文献1来掌握该模块的学习。当掌握了 Twisted 的这些基础后,在来看 Scrapy 的代码就会一目了然。下一小节我们将继续剖析 Scrapy 的中间件模块,进一步学习 Scrapy 框架源码。
4. 参考文献
- 还没有人评论,欢迎说说您的想法!
 客服
客服


