


Scrapy 中的 Pipline管道
本小节中我们将详细介绍 Scrapy 中的 Pipeline 及其多种用法和使用场景。Pipeline 是 Scrapy 框架的一个重要模块,从前面的 Scrapy 架构图中我们可以看到它位于架构图的最左边,用于连续处理从网页中抓取到的每条记录,就像一个流水线工厂加工食品那样,完成食品最后的封装、保存等操作。此外,我们还会介绍 Scrapy 内置的图片管道,可以自动下载对应地址的图片。最后,我们会基于上述内容完成一个小说网站的爬取案例。
1. Scrapy 中的 Pipeline 介绍
Pipeline 的中文意思是管道,类似于工厂的流水线那样。Scrapy 中的 Pipeline 通常是和 Items 联系在一起的,其实就是对 Items 数据的流水线处理。 一般而言,Pipeline 的典型应用场景如下:
- 数据清洗、去重;
- 验证数据的有效性;
- 按照自定义格式保存数据;
- 存储到合适的数据库中 (如 MySQL、Redis 或者 MongoDB);
通过前面的 Scrapy 架构图可知,Pipeline 位于 Scrapy 数据处理流程的最后一步,但是它也不是必须,Pipeline 默认处于关闭状态。如果需要的话,我们只需要在 settings.py 中设置 ITEM_PIPELINES 属性值即可。它是一个数组值,我们可以定义多个 Item Pipeline,并且在 ITEM_PIPELINES 中设置相应 Pipeline 的优先级。这样 Scrapy 会依次处理这些 Pipelines,最后达到我们想要的效果。
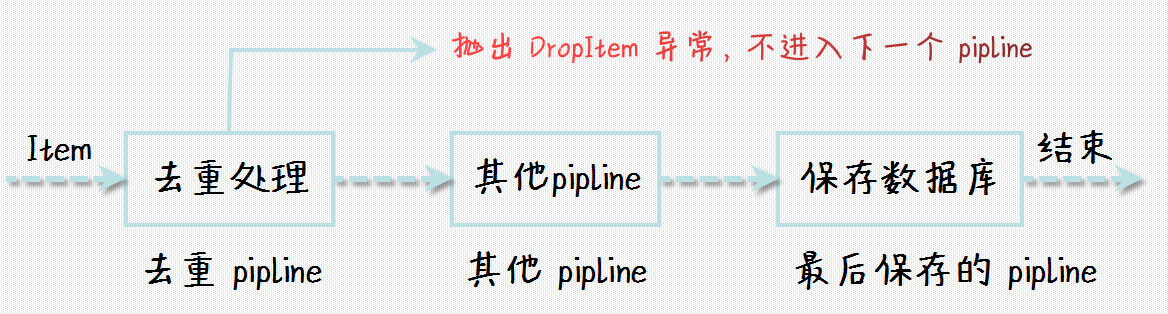
注意:上面的 pipeline 顺序和功能都可以任意调整,保证逻辑性即可。比如有一个去重的 pipeline 和保存到数据库的 pipeline,那么去重的 pipeline 一定要在保存数据库之前,这样保存的就是不重复的数据。
2. 如何编写自己的 Item Pipeline
编写自己的 Item Pipeline 非常简单,我们只需要编写一个简单的类,实现四个特定名称的方法即可 (部分方法非必须)。我们来简单说明下这三个方法:
- open_spider(spider):非必需,参数 spider 即被关闭的 Spider 对象。这个方法是 MiddlewareManager 类中的方法,在 Spider 开启时被调用,主要做一些初始化操作,如连接数据库、打开要保存的文件等;
- close_spider(spider):非必需,参数 spider 即被关闭的 Spider 对象。这个方法也是 MiddlewareManager 类中的方法,在 Spider 关闭时被调用,主要做一些如关闭数据库连接、关闭打开的文件等操作;
- from_crawler(cls, crawler):非必需,在 Spider启用时调用,且早于 open_spider() 方法。这个方法我们很少去重载,可以不用;
- process_item(item, spider):必须实现。该函数有两个参数,一个是表示被处理的 Item 对象,另一个是生成该 Item 的 Spider 对象。定义的 Item pipeline 会默认调用该方法对 Item 进行处理,这也是 Pipeline 的工作核心;
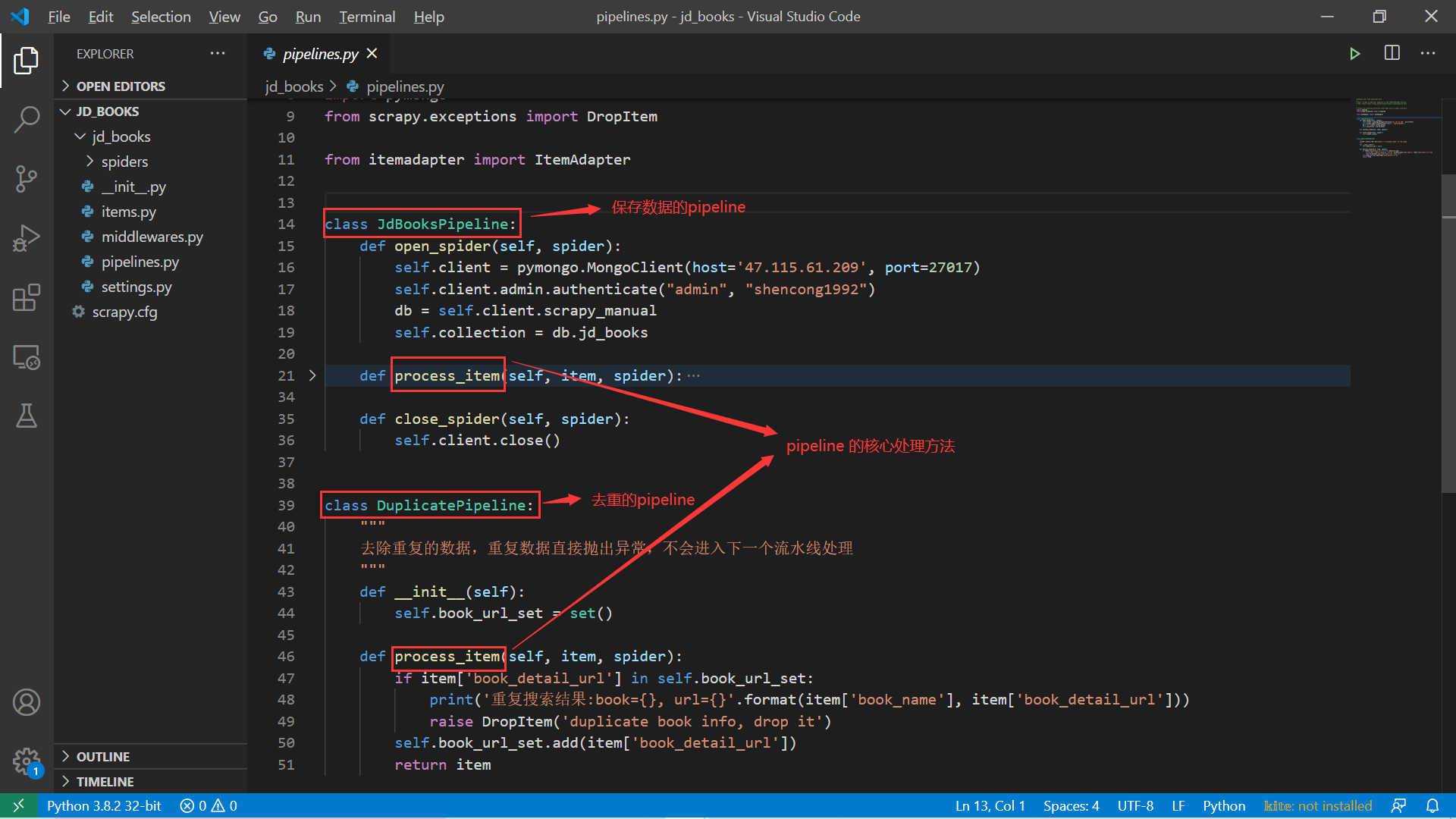
完成这样一个 Item Pipeline 后,将该类的路径地址添加到 settings.py 中的 ITEM_PIPELINES 中即可。下图是我们一个简单项目完成的两个 pipelines。
3. 实战演练
学习了上面的一些知识,我们来使用一个简单的网站进行实战演练,在该过程中介绍更多的和 Item Pipeline 相关的用法。
假设我们是一名小说爱好者,我想到起点中文网上去找一些好的小说看,我该怎么找呢?起点中文网的月票榜是一个不错的参考方式,如下图所示:

其实简单看一看就知道月票榜的 url 组成:
- 主体 url:https://www.qidian.com/rank/yuepiao
- 参数 month:02 表示 2 月份,03 表示 3 月份,目前为止最多到 7 月份;
- 参数 chn:表示的是分类,-1 表示全部分类。21 表示玄幻,22表示仙侠;
- 参数 page:表示第几页,一页有20个作品。
目前我们只需要从 01 月份开始到 07 月份的月票榜中,每次都取得第一页的数据,也就是月票榜的前20 名。7 个月份的前 20 名加起来,然后再去重,就得到了曾经的占据月票榜的作品,这中间大概率都是比较好看的书。完成这个简单的需求我们按照如下的步骤进行:
创建初始项目 qidian_yuepiao:
[root@server ~]# pyenv activate scrapy-test
(scrapy-test) [root@server ~]# cd scrapy-test
(scrapy-test) [root@server scrapy-test]# scrapy startproject qidian_yuepia
(scrapy-test) [root@server qidian_yuepiao]# ls
__init__.py items.py middlewares.py pipelines.py settings.py spider
接下来我们准备获取小说作品的字段,大概会获取如下几个数据:
- 小说名:name;
- 小说作者:author;
- 小说类型:fiction_type。比如玄幻、仙侠、科幻等;
- 小说状态:state。连载还是完结;
- 封面图片地址:image_url;
- images:保存图片数据;
- brief_introduction:作品简介;
- book_url:小说的具体地址。
根据定义的这些字段,我们可以写出对应的 Items 类,如下:
(scrapy-test) [root@server qidian_yuepiao]# cat items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class QidianYuepiaoItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
author = scrapy.Field()
fiction_type = scrapy.Field()
state = scrapy.Field()
image_url = scrapy.Field()
images = scrapy.Field()
brief_introduction = scrapy.Field()
book_url = scrapy.Field()
到了最关键的地方,需要解析网页数据,提取月票榜的作品信息。这个和前面一些,我们只需要完成相应的 xpath 即可。此外,我们会从 01 月份的月票榜开始,每次会新生成一个 url,主要改动的就是月份参数,每次将月份数加一;如果当前月份大于07,则终止。
(scrapy-test) [root@server qidian_yuepiao]# touch spiders/qidian_yuepiao_parse.py
import re
from scrapy import Request
from scrapy.spiders import Spider
from qidian_yuepiao.items import QidianYuepiaoItem
def num_to_str(num, size=2, padding='0'):
"""
0 - > 00 1 -> 01 11 -> 11
:param num:
:param size:
:param padding:
:return:
"""
str_num = str(num)
while len(str_num) < size:
str_num = padding + str_num
return str_num
class QidianSpider(Spider):
name = "qidian_yuepiao_spider"
start_urls = [
"https://www.qidian.com/rank/yuepiao?month=01&chn=-1&page=1"
]
def parse(self, response):
fictions = response.xpath('//div[@id="rank-view-list"]/div/ul/li')
for fiction in fictions:
name = fiction.xpath('div[@class="book-mid-info"]/h4/a/text()').extract_first()
author = fiction.xpath('div[@class="book-mid-info"]/p[@class="author"]/a[1]/text()').extract_first()
fiction_type = fiction.xpath('div[@class="book-mid-info"]/p[@class="author"]/a[1]/text()').extract_first()
# 注意一定要是列表,不然会报错
image_url = ['http:{}'.format(fiction.xpath('div[@class="book-img-box"]/a/img/@src').extract()[0])]
brief_introduction = fiction.xpath('div[@class="book-mid-info"]/p[@class="intro"]/text()').extract_first()
state = fiction.xpath('div[@class="book-mid-info"]/p[@class="author"]/a[2]/text()').extract()[0]
book_url = fiction.xpath('div[@class="book-mid-info"]/h4/a/@href').extract()[0]
item = QidianYuepiaoItem()
item['name'] = name
item['author'] = author
item['fiction_type'] = fiction_type
item['brief_introduction'] = brief_introduction.strip()
item['image_url'] = image_url
item['state'] = state
item['book_url'] = book_url
yield item
# 提取月份数,同时也要提取请求的url
url = response.url
regex = "https://(.*)?month=(.*?)&(.*)"
pattern = re.compile(regex)
m = pattern.match(url)
if not m:
return []
prefix = m.group(1)
month = int(m.group(2))
suffix = m.group(3)
# 大于7月份则停止,目前是2020年7月20日
if month > 7:
return
# 一定要将月份转成01, 02, s03这样的形式,否则不能正确请求到数据
next_month = num_to_str(month + 1)
next_url = f"https://{prefix}?month={next_month}&{suffix}"
yield Request(next_url)
最后到了我们本节课的重点。首先我想要将数据保存成 json 格式,存储到文本文件中,但是在保存之前,需要对作品去重。因为有些作品会连续好几个月出现在月票榜的前20位置上,会有比较多重复。我们通过作品的 url 地址来唯一确定该小说。因此需要定义两个 Item Pipeline:
import json
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
class QidianYuepiaoPipeline:
"""
保存不重复的数据到文本中
"""
def open_spider(self, spider):
self.file = open("yuepiao_top.json", 'w+')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
data = json.dumps(dict(item), ensure_ascii=False)
self.file.write(f"{data}n")
return item
class DuplicatePipeline:
"""
去除重复的数据,重复数据直接抛出异常,不会进入下一个流水线处理
"""
def __init__(self):
self.book_url_set = set()
def process_item(self, item, spider):
if item['book_url'] in self.book_url_set:
raise DropItem('duplicate fiction, drop it')
self.book_url_set.add(item['book_url'])
return item
我来简单介绍下上面实现的两个 pipelines 的代码。首先爬虫抓取的 item 结果经过的是 DuplicatePipeline 这个管道 (我们通过管道的优先级控制),我们在 DuplicatePipeline 中定义了一个全局的集合 (set),在 管道的核心方法process_item() 中,我们先判断传过来的 item 中 book_url 的值是否存在,如果存在则判定重复,然后抛出异常,这样下一个管道 (即 QidianYuepiaoPipeline) 就不会去处理;
在经过的第二个管道 (QidianYuepiaoPipeline) 中,我们主要是将不重复 item 保存到本地文件中,因此我们会在 open_spider() 方法中打开文件句柄,在 close_spider() 方法中关闭文件句柄,而在 process_item() 中将 item 数据保存到指定的文件中。
接着就是将这两个 Pipelines 加到 settings.py 中:
ITEM_PIPELINES = {
'qidian_yuepiao.pipelines.DuplicatePipeline': 200,
'qidian_yuepiao.pipelines.QidianYuepiaoPipeline': 300,
}
最后,我们来介绍一个 Scrapy 内置的图片管道,其实现的 Pipeline 代码位置为:scrapy/pipelines/images.py,对应的还有一个内置的文件管道。我们不需要编写任何代码,只需要在 settings.py 中指定下载的图片字段即可:
# 下载图片存储位置
IMAGES_STORE = '/root/scrapy-test/qidian_yuepiao/qidian_yuepiao/images'
# 保存下载图片url地址的字段
IMAGES_URLS_FIELD = 'image_url'
# 图片保存地址字段
IMAGES_RESULT_FIELD = 'images'
IMAGES_THUMBS = {
'small': (102, 136),
'big': (150, 200)
}
# ...
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
'qidian_yuepiao.pipelines.DuplicatePipeline': 200,
'qidian_yuepiao.pipelines.QidianYuepiaoPipeline': 300,
}
由于 ImagesPipeline 继承自 FilesPipeline,我们可以从官网的介绍中知道该图片下载功能的执行流程如下:
- 在 spider 中爬取需要下载的图片链接,将其放入 item 的 image_url 字段中;
- spider 将得到的 item 传送到 pipeline 进行处理;
- 当 item 到达 Image Pipeline 处理时,它会检测是否有 image_url 字段,如果存在的话,会将该 url 传递给 scrapy 调度器和下载器;
- 下载完成后会将结果写入 item 的另一个字段 images,images 包含了图片的本地路径、图片校验、以及图片的url;
完成了以上四步之后,我们的这样一个简单需求就算完成了。还等什么,快来运行看看!以下是视频演示:
这样爬取数据是不是非常有趣?使用了 Scrapy 框架后,我们的爬取流程会变得比较固定化以及流水线化。但我们不仅仅要学会怎么使用 Scrapy 框架,还要能够基于 Scrapy 框架在特定场景下做些改造,这样才能达到完全驾驭 Scrapy 框架的目的。
4. 小结
本小节中,我们介绍了 Scrapy 中 Pipeline 相关的知识并在起点中文网上进行了简单的演示。在我们的爬虫项目中使用了两个自定义管道,分别用于去除重复小说以及将非重复的小说数据保存到本地文件中;另外我们还启用了 Scrapy 内置的图片下载管道,帮助我们自动处理图片 URL 并下载。
- 还没有人评论,欢迎说说您的想法!
 客服
客服


