


Scrapy 常用命令及其分析
今天这一节我们来介绍 Scrapy 框架的常用命令,同时会分析这些命令的执行过程,彻底掌握这些常用命令操作。这些命令是 Scrapy 框架的一个常用操作,我们会在后面经常使用它们。
1. Scrapy 常用命令介绍
在前面互动出版网的爬虫实例中我们使用过两个 Scrapy 的命令,分别为:startproject 和 crawl,分别表示创建 Scrapy 项目和执行 Scrapy 爬虫工程。此外,在上节中我们还使用了 scrapy shell 命令进入交互式模式操作。今天我们首先来介绍 Scrapy 中所支持的命令及其功能:
1.1 全局命令
-
startproject:其语法为
scrapy startproject 项目名。该命令用于在当前目录下创建对应命名的 scrapy 爬虫项目; -
settings: 其语法为
scrapy settings [options],该命令会输出 Scrapy 的默认配置值。当然也可以单独输出 options 的值。我们来看一个简单的示例:(scrapy-test) [root@server china_pub]# scrapy settings --get=USER_AGENT Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36 -
runspider:语法格式为
scrapy runspider 爬虫文件,该命令会在未创建项目的情况下运行一个 spider; -
shell:进入交互式模式,可以带上 URL 参数。表示会打开这个 URL 并将结果保存到 response 中,方便后续测试;
-
fetch:使用下载器下载指定的 URL,并将获取到的内容输出到控制台;
-
view:该命令可以用来检查 spider 所获取到的页面,使用格式为
scrapy view <url>; -
version:获取 Scrapy 框架的版本信息,可以配合 -v 选项,输出 Python 等更多信息。
1.2 项目命令
-
crawl: 使用项目中的 Spider 进行爬取,该命令要求输入启动的 spider 名称;
# 命令格式, 带的参数是: [spider名称] (scrapy-test) [root@server china_pub]# scrapy crawl China-Pub-Crawler # ... -
check:运行 contract 检查;
(scrapy-test) [root@server china_pub]# scrapy check ---------------------------------------------------------------------- Ran 0 contracts in 0.000s OK -
list:列出当前项目中所有可用的 spider;
(scrapy-test) [root@server china_pub]# scrapy list China-Pub-Crawler -
genspider:在当前项目中创建 spider。该方法可以使用提前定义好的模板来生成相应的 spider,也可以自己创建 spider 源码文件;我们来看一个简单的示例:
(scrapy-test) [root@server scrapy-test]# mkdir genspider (scrapy-test) [root@server scrapy-test]# cd genspider/ (scrapy-test) [root@server genspider]# ls # 使用genspider命令创建spider文件 (scrapy-test) [root@server genspider]# scrapy genspider qidian_yuepiao www.qidian.com Created spider 'qidian_yuepiao' using template 'basic' (scrapy-test) [root@server genspider]# ls qidian_yuepiao.py (scrapy-test) [root@server genspider]# cat qidian_yuepiao.py import scrapy class QidianYuepiaoSpider(scrapy.Spider): name = 'qidian_yuepiao' allowed_domains = ['www.qidian.com'] start_urls = ['http://www.qidian.com/'] def parse(self, response): pass上面的操作可以看到,我们使用 scrapy 的 genspider 生成了 spider 文件,这个 spider 文件内定义了
QidianYuepiaoSpider这个爬虫类,爬虫名称是我们输入的第一个参数,允许的爬取域名和起始的 urls 是根据第二个参数得到的。
2. Scrapy 常用命令源码分析
这一部分内容我们将分析上面介绍的命令的执行过程,从源码角度来审视这些命令行操作过程。
2.1 Scrapy command 的执行过程
首先查看 Scrapy 命令的代码,其内容如下:
# 查看scrapy的命令文件位置
[root@server2 ~]# which scrapy
/usr/local/bin/scrapy
# 查看命令文件内的代码
[root@server2 ~]# cat /usr/local/bin/scrapy
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import re
import sys
from scrapy.cmdline import execute
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script.pyw?|.exe)?$', '', sys.argv[0])
sys.exit(execute())
是不是很简单?不过深入下去就复杂了。我们来看这个最关键的 execute()方法:
# 源码位置:scrapy/cmdline.py
# ...
def execute(argv=None, settings=None):
if argv is None:
argv = sys.argv
# 设置配置参数
if settings is None:
settings = get_project_settings()
# set EDITOR from environment if available
try:
editor = os.environ['EDITOR']
except KeyError:
pass
else:
settings['EDITOR'] = editor
inproject = inside_project()
# 这里是导入所有scrapy支持的命令
cmds = _get_commands_dict(settings, inproject)
# 这里是要执行的子命令名,比如startproject、crawl等
cmdname = _pop_command_name(argv)
# 可以额外加上一行打印语句
# print("inproject={}, cmds={}, cmdname={}".format(inproject, cmds, cmdname))
# 解析命令行参数选项
parser = optparse.OptionParser(formatter=optparse.TitledHelpFormatter(),
conflict_handler='resolve')
if not cmdname:
'''没有带子命令,打印帮助命令后退出'''
_print_commands(settings, inproject)
sys.exit(0)
elif cmdname not in cmds:
'''未知子命令,打印错误信息后退出'''
_print_unknown_command(settings, cmdname, inproject)
sys.exit(2)
# 取出这个对应命令文件的Command类,其需要区分是否在爬虫项目中
cmd = cmds[cmdname]
parser.usage = "scrapy %s %s" % (cmdname, cmd.syntax())
parser.description = cmd.long_desc()
settings.setdict(cmd.default_settings, priority='command')
# 设置相关
cmd.settings = settings
cmd.add_options(parser)
# 解析子命令带的参数
opts, args = parser.parse_args(args=argv[1:])
# 处理子命令参数
_run_print_help(parser, cmd.process_options, args, opts)
# 核心,设置command类的核心处理类
cmd.crawler_process = CrawlerProcess(settings)
# 会调用command类的run()方法执行
_run_print_help(parser, _run_command, cmd, args, opts)
sys.exit(cmd.exitcode)
这个函数是所有 scrapy 命令要执行的函数,函数中得到的 cmds 是 scrapy/command 下所有或部分 Command 类集合,也即表示 scrapy 所支持的命令操作。我们可以手动在其后面打印一条语句 (上面注释的 print() 方法),来看看 cmds 的具体值:
# 这个时候新建scrapy项目,inproject=False
[root@server2 shen]# scrapy startproject qidian_spider
inproject=False, cmds={'commands': <scrapy.commands.BaseRunSpiderCommand object at 0x7ff3b3231470>, 'bench': <scrapy.commands.bench.Command object at 0x7ff3b3223be0>, 'fetch': <scrapy.commands.fetch.Command object at 0x7ff3b32cb080>, 'genspider': <scrapy.commands.genspider.Command object at 0x7ff3b32c6b00>, 'runspider': <scrapy.commands.runspider.Command object at 0x7ff3b32c6e48>, 'settings': <scrapy.commands.settings.Command object at 0x7ff3b32c6ac8>, 'shell': <scrapy.commands.shell.Command object at 0x7ff3b32c6a90>, 'startproject': <scrapy.commands.startproject.Command object at 0x7ff3b32c69e8>, 'version': <scrapy.commands.version.Command object at 0x7ff3b32c6940>, 'view': <scrapy.commands.view.Command object at 0x7ff3b32c6978>}, cmdname=startproject
New Scrapy project 'qidian_spider', using template directory '/usr/local/lib64/python3.6/site-packages/scrapy/templates/project', created in:
/root/shen/qidian_spider
You can start your first spider with:
cd qidian_spider
scrapy genspider example example.com
注意到这是在没有 scrapy 项目时执行的,我们在创建了上述项目之后,进入 qidian_spider 爬虫项目目录中,在继续执行:
# 进入到scrapy项目内,此时在运行scrapy命令时,inproject=True
[root@server2 qidian_spider]# scrapy list
inproject=True, cmds={'commands': <scrapy.commands.BaseRunSpiderCommand object at 0x7fed7be984e0>, 'bench': <scrapy.commands.bench.Command object at 0x7fed7be8bc50>, 'check': <scrapy.commands.check.Command object at 0x7fed7bf32128>, 'crawl': <scrapy.commands.crawl.Command object at 0x7fed7bf2cba8>, 'edit': <scrapy.commands.edit.Command object at 0x7fed7bf2cb70>, 'fetch': <scrapy.commands.fetch.Command object at 0x7fed7bf2c860>, 'genspider': <scrapy.commands.genspider.Command object at 0x7fed7bf2c8d0>, 'list': <scrapy.commands.list.Command object at 0x7fed7bf2cb00>, 'parse': <scrapy.commands.parse.Command object at 0x7fed7bf2cac8>, 'runspider': <scrapy.commands.runspider.Command object at 0x7fed7beae908>, 'settings': <scrapy.commands.settings.Command object at 0x7fed7beaea58>, 'shell': <scrapy.commands.shell.Command object at 0x7fed7beaeac8>, 'startproject': <scrapy.commands.startproject.Command object at 0x7fed7beaeba8>, 'version': <scrapy.commands.version.Command object at 0x7fed7beaebe0>, 'view': <scrapy.commands.view.Command object at 0x7fed7beaec50>}, cmdname=list
有点理解了吧?在爬虫项目之外的,支持10个命令;创建了爬虫项目后,进入到项目中后,则支持前面所有的命令。这里 inproject 值就是判断执行的 scrapy 命令是否在项目内的。
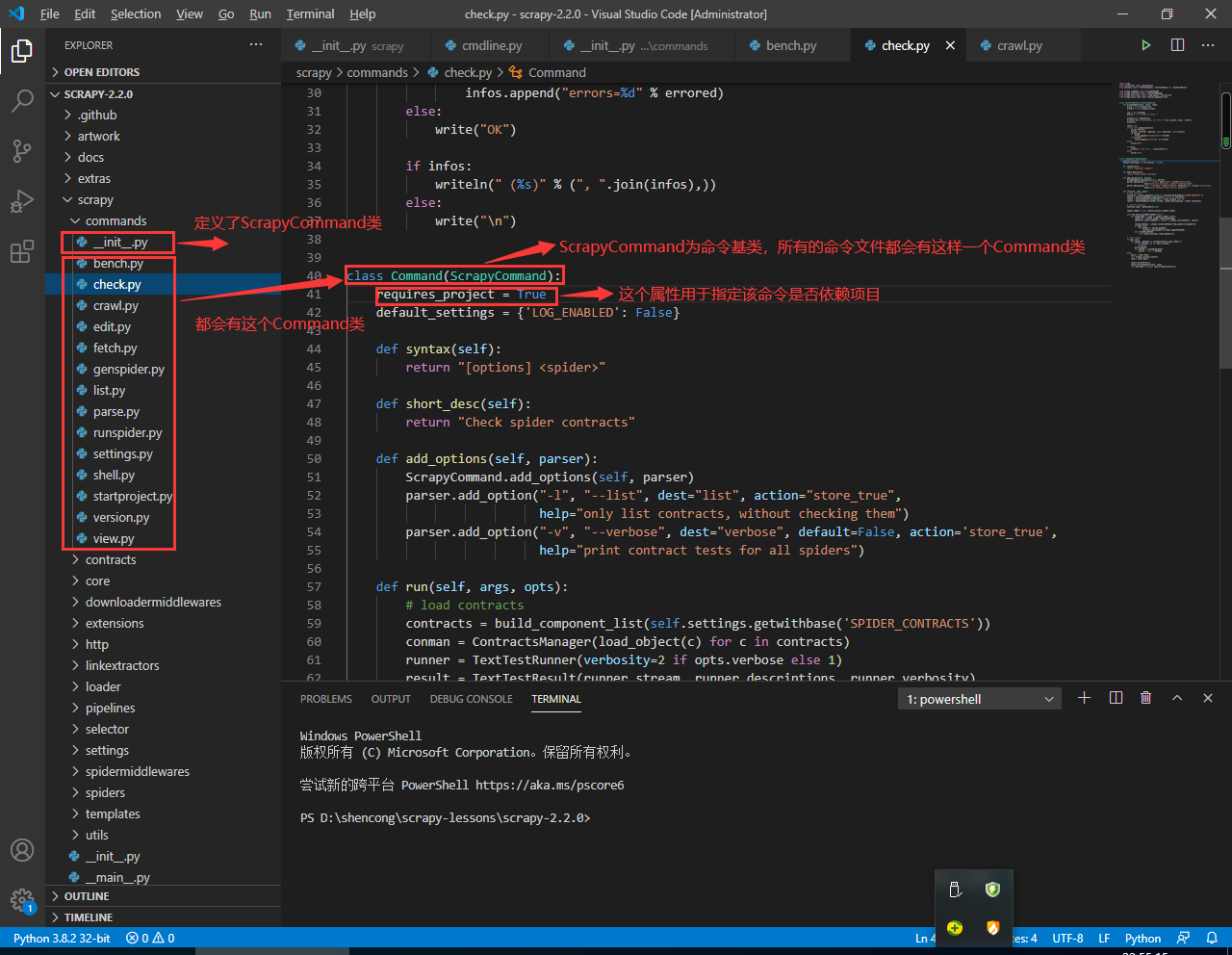
在·commands 目录下的 __init__.py 文件中定义了 ScrapyCommand 基类,然后所有命令文件中都会定义 Command 类,用于描述对应命令。该类统一都继承自 ScrapyCommand 类,且有一个 requires_project 属性来辅助判断该命令是否依赖 project。这个属性正是控制下面语句执行的结果:
cmds = _get_commands_dict(settings, inproject)
关联的函数如下:
# 源码位置:scrapy/cmdline.py
# ...
def _get_commands_from_module(module, inproject):
d = {}
for cmd in _iter_command_classes(module):
# 这里inproject为True表示在项目内,此时if条件全部满足;
# inproject为False时,只有命令文件中Command类的requires_project属性为False时才执行if语句
if inproject or not cmd.requires_project:
cmdname = cmd.__module__.split('.')[-1]
d[cmdname] = cmd()
return d
# ...
def _get_commands_dict(settings, inproject):
# 看上面的函数,如何得到cmds?
cmds = _get_commands_from_module('scrapy.commands', inproject)
cmds.update(_get_commands_from_entry_points(inproject))
cmds_module = settings['COMMANDS_MODULE']
if cmds_module:
cmds.update(_get_commands_from_module(cmds_module, inproject))
return cmds
# ...
在回到前面的 execute() 方法中,由我们前面给出的注释来看,最核心的代码就是如下两句:
# ...
def execute(argv=None, settings=None):
# ...
# 核心,设置command类的核心处理类
cmd.crawler_process = CrawlerProcess(settings)
# 会调用command类的run()方法执行
_run_print_help(parser, _run_command, cmd, args, opts)
# ...
我们知道 cmd 表示的正是对应命令文件下的 Command 类实例,它的一个很重要的属性就是 crawler_process, 后面我们也会介绍到它。接下来的执行代码正是第二句,我们继续跟踪调用其方法:
# 源码位置:scrapy/cmdline.py
# ...
def _run_print_help(parser, func, *a, **kw):
try:
func(*a, **kw)
except UsageError as e:
if str(e):
parser.error(str(e))
if e.print_help:
parser.print_help()
sys.exit(2)
看到没,前面的语句等价于执行 _run_command(cmd, args, opts),继续跟踪 _run_command() 方法:
# 源码位置:scrapy/cmdline.py
# ...
def _run_command(cmd, args, opts):
if opts.profile:
_run_command_profiled(cmd, args, opts)
else:
# 通常情况下执行这里的run()方法
cmd.run(args, opts)
一般情况代码是执行下面的 cmd.run() 方法。至此,答案已经呼之欲出了。Scrapy 命令的执行就是调用对应命令文件下的 Command 类中的 run() 方法。
2.2 startproject 的执行过程
上一小节中介绍了对应的命令执行的内容是 Command 类下的 run 方法,接下来我们就来探究下 startproject 命令的执行过程,看它是如何给我们生成那些代码文件的。
# 源码位置: scrapy/commands/startproject.py
class Command(ScrapyCommand):
requires_project = False
default_settings = {'LOG_ENABLED': False,
'SPIDER_LOADER_WARN_ONLY': True}
# ...
def run(self, args, opts):
if len(args) not in (1, 2):
raise UsageError()
# 获取项目名称,选项中带的
project_name = args[0]
# 项目所在目录
project_dir = args[0]
# 第二个参数的话会重新指定项目目录
if len(args) == 2:
project_dir = args[1]
# 如果存在 scrapy.cfg 则会直接提示错误并返回
if exists(join(project_dir, 'scrapy.cfg')):
self.exitcode = 1
print('Error: scrapy.cfg already exists in %s' % abspath(project_dir))
return
# 判断是否是合适的项目名
if not self._is_valid_name(project_name):
self.exitcode = 1
return
self._copytree(self.templates_dir, abspath(project_dir))
move(join(project_dir, 'module'), join(project_dir, project_name))
for paths in TEMPLATES_TO_RENDER:
path = join(*paths)
tplfile = join(project_dir, string.Template(path).substitute(project_name=project_name))
render_templatefile(tplfile, project_name=project_name, ProjectName=string_camelcase(project_name))
# 一些print语句
print("New Scrapy project '%s', using template directory '%s', "
"created in:" % (project_name, self.templates_dir))
print(" %sn" % abspath(project_dir))
print("You can start your first spider with:")
print(" cd %s" % project_dir)
print(" scrapy genspider example example.com")
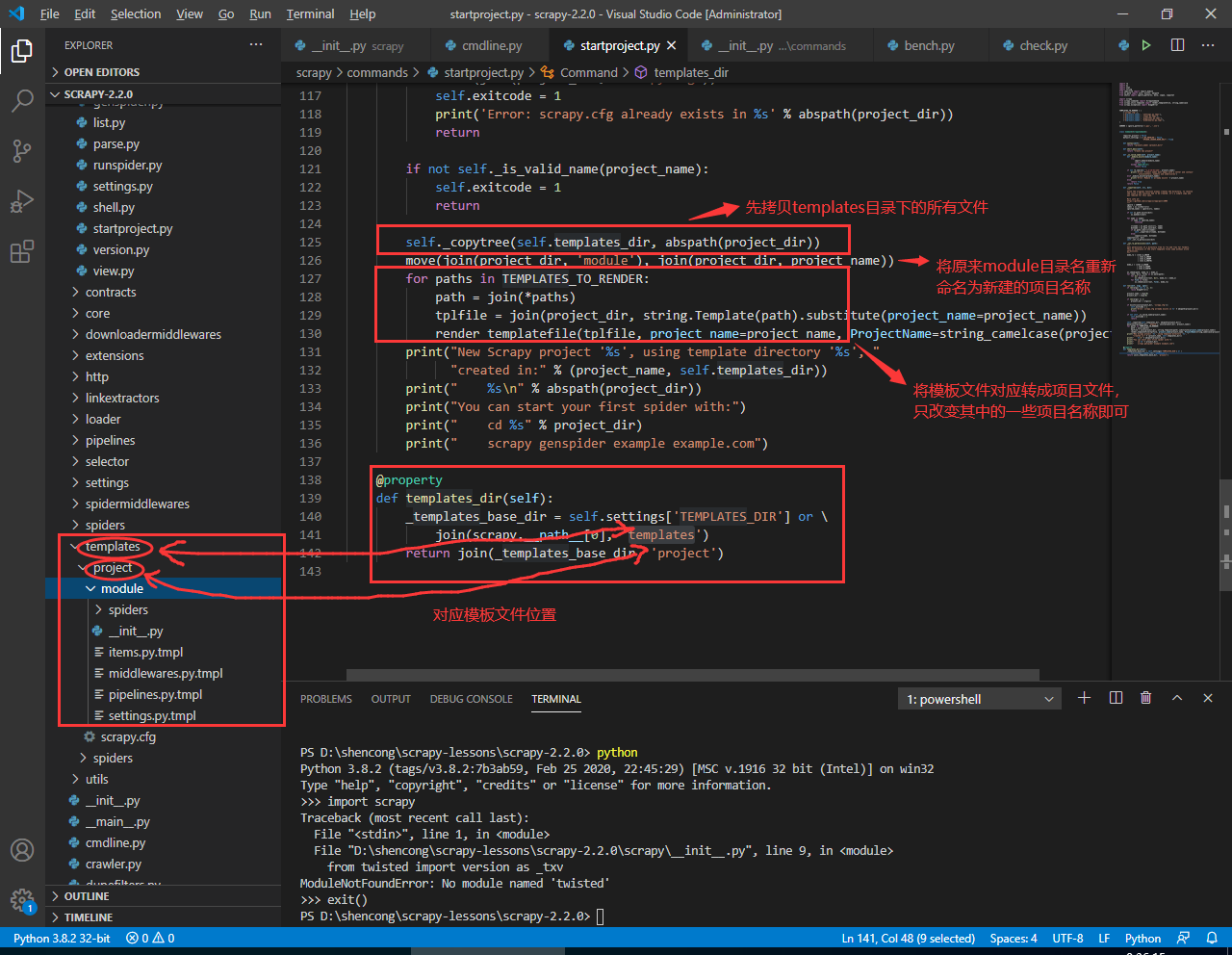
看这两条语句,在上图中也做了相应的注释:
self._copytree(self.templates_dir, abspath(project_dir))
move(join(project_dir, 'module'), join(project_dir, project_name))
第一条语句是递归拷贝源码 scrapy/templates 目录下的所有文件到新建的项目目录中;第二句便是将拷贝过来中的 module 目录替换成项目名称。接下来,便是使用 for 循环将模板文件中的项目名的变量进行替换:
# 源码位置:scrapy/commands/startproject.py
# ...
TEMPLATES_TO_RENDER = (
('scrapy.cfg',),
('${project_name}', 'settings.py.tmpl'),
('${project_name}', 'items.py.tmpl'),
('${project_name}', 'pipelines.py.tmpl'),
('${project_name}', 'middlewares.py.tmpl'),
)
class Command(ScrapyCommand):
# ...
def run(self, args, opts):
# ...
for paths in TEMPLATES_TO_RENDER:
path = join(*paths)
tplfile = join(project_dir, string.Template(path).substitute(project_name=project_name))
render_templatefile(tplfile, project_name=project_name, ProjectName=string_camelcase(project_name))
# ...
这个模板替换方法也非常简单,就是使用了 Python 中内置的 string.Template 类来完成:
# 源码位置:scrapy/utils/template.py
def render_templatefile(path, **kwargs):
with open(path, 'rb') as fp:
raw = fp.read().decode('utf8')
content = string.Template(raw).substitute(**kwargs)
render_path = path[:-len('.tmpl')] if path.endswith('.tmpl') else path
with open(render_path, 'wb') as fp:
fp.write(content.encode('utf8'))
if path.endswith('.tmpl'):
os.remove(path)
# ...
看到这里,大家对 scrapy startproject project_name 这条命令背后的执行过程是不是有了更深的了解?
2.3 shell 命令的执行过程
我们在上一节中介绍了 scrapy shell [url] 这样的指令,它帮助我们进入交互模式去执行调试获取网页的 xpath 表达式。我们有没有想过这个命令背后的原理?今天我们专门学习了 Scrapy Command,那么就正好借此机会看看 scrapy shell [url] 这条命令背后的原理是什么。根据前面跟踪代码的经验,我们可以直接定位到 scrapy/commands/shell.py 下 Command 类中的 run() 方法即可:
# 源码位置: scrapy/commands/shell.py
# ...
class Command(ScrapyCommand):
# ...
def run(self, args, opts):
url = args[0] if args else None
if url:
# first argument may be a local file
url = guess_scheme(url)
spider_loader = self.crawler_process.spider_loader
spidercls = DefaultSpider
if opts.spider:
spidercls = spider_loader.load(opts.spider)
elif url:
# 如果传入了url参数,后面需要做请求
spidercls = spidercls_for_request(spider_loader, Request(url),
spidercls, log_multiple=True)
crawler = self.crawler_process._create_crawler(spidercls)
crawler.engine = crawler._create_engine()
crawler.engine.start()
# 启动爬虫线程爬取url
self._start_crawler_thread()
shell = Shell(crawler, update_vars=self.update_vars, code=opts.code)
shell.start(url=url, redirect=not opts.no_redirect)
def _start_crawler_thread(self):
t = Thread(target=self.crawler_process.start,
kwargs={'stop_after_crawl': False})
t.daemon = True
t.start()
其实上面代码的执行逻辑是比较简单的,总的来说就做了2件事情:
- 创建 scrapy 引擎并单独启动一个线程,后台运行;
- 启动 shell 线程;
我们来关注下 Shell 这个类:
# 源码位置:scrapy/shell.py
# ...
class Shell:
# ...
def start(self, url=None, request=None, response=None, spider=None, redirect=True):
# disable accidental Ctrl-C key press from shutting down the engine
signal.signal(signal.SIGINT, signal.SIG_IGN)
if url:
self.fetch(url, spider, redirect=redirect)
elif request:
self.fetch(request, spider)
elif response:
request = response.request
self.populate_vars(response, request, spider)
else:
self.populate_vars()
if self.code:
print(eval(self.code, globals(), self.vars))
else:
"""
Detect interactive shell setting in scrapy.cfg
e.g.: ~/.config/scrapy.cfg or ~/.scrapy.cfg
[settings]
# shell can be one of ipython, bpython or python;
# to be used as the interactive python console, if available.
# (default is ipython, fallbacks in the order listed above)
shell = python
"""
cfg = get_config()
section, option = 'settings', 'shell'
env = os.environ.get('SCRAPY_PYTHON_SHELL')
shells = []
if env:
shells += env.strip().lower().split(',')
elif cfg.has_option(section, option):
shells += [cfg.get(section, option).strip().lower()]
else: # try all by default
shells += DEFAULT_PYTHON_SHELLS.keys()
# always add standard shell as fallback
shells += ['python']
start_python_console(self.vars, shells=shells,
banner=self.vars.pop('banner', ''))
从上面的代码我们可以看到一点,当传入的参数有 url 或者 request 时,会调用 fetch() 方法去下载网页数据,它会调用 twisted 框架中的 threads 来执行网页的下载动作,并设置变量 response 。这就是为什么我们能在 scrapy shell 中直接使用 response 获取下载网页内容的原因。
# 源码位置:scrapy/shell.py
# ...
class Shell:
# ...
def fetch(self, request_or_url, spider=None, redirect=True, **kwargs):
from twisted.internet import reactor
if isinstance(request_or_url, Request):
request = request_or_url
else:
url = any_to_uri(request_or_url)
request = Request(url, dont_filter=True, **kwargs)
if redirect:
request.meta['handle_httpstatus_list'] = SequenceExclude(range(300, 400))
else:
request.meta['handle_httpstatus_all'] = True
response = None
try:
response, spider = threads.blockingCallFromThread(
reactor, self._schedule, request, spider)
except IgnoreRequest:
pass
# 设置response结果
self.populate_vars(response, request, spider)
def populate_vars(self, response=None, request=None, spider=None):
import scrapy
self.vars['scrapy'] = scrapy
self.vars['crawler'] = self.crawler
self.vars['item'] = self.item_class()
self.vars['settings'] = self.crawler.settings
self.vars['spider'] = spider
self.vars['request'] = request
self.vars['response'] = response
if self.inthread:
self.vars['fetch'] = self.fetch
self.vars['view'] = open_in_browser
self.vars['shelp'] = self.print_help
self.update_vars(self.vars)
if not self.code:
self.vars['banner'] = self.get_help()
# ...
继续跟踪前面的 start() 方法,很明显我们的核心函数就是一句:
start_python_console(self.vars, shells=shells,
banner=self.vars.pop('banner', ''))
self.vars 就是需要带到 shell 环境中的变量,shells 是我们选择交互的环境,后面可以看到总共支持4种交互环境,分别是 ptpython、ipython、ipython、和 python。banner 参数则表示进入交互模式是给出的提示语句。我们来看 start_python_console() 方法的源码:
# 源码位置:scrapy/utils/console.py
# ...
DEFAULT_PYTHON_SHELLS = OrderedDict([
('ptpython', _embed_ptpython_shell),
('ipython', _embed_ipython_shell),
('bpython', _embed_bpython_shell),
('python', _embed_standard_shell),
])
def get_shell_embed_func(shells=None, known_shells=None):
"""Return the first acceptable shell-embed function
from a given list of shell names.
"""
if shells is None: # list, preference order of shells
shells = DEFAULT_PYTHON_SHELLS.keys()
if known_shells is None: # available embeddable shells
known_shells = DEFAULT_PYTHON_SHELLS.copy()
for shell in shells:
if shell in known_shells:
try:
# function test: run all setup code (imports),
# but dont fall into the shell
return known_shells[shell]()
except ImportError:
continue
def start_python_console(namespace=None, banner='', shells=None):
"""Start Python console bound to the given namespace.
Readline support and tab completion will be used on Unix, if available.
"""
if namespace is None:
namespace = {}
try:
shell = get_shell_embed_func(shells)
if shell is not None:
shell(namespace=namespace, banner=banner)
except SystemExit: # raised when using exit() in python code.interact
pass
通过分析代码可知:get_shell_embed_func() 方法最终会返回 DEFAULT_PYTHON_SHELLS 中对应值得那个,比如我们传入的 shells 值为 ['python'],则最后返回 _embed_standard_shell() 这个函数。最后就是调用这个函数,即可得到 scrapy shell 的交互模式。来最后看一看 _embed_standard_shell() 这个神奇的方法:
# 源码位置:scrapy/utils/console.py
# ...
def _embed_standard_shell(namespace={}, banner=''):
"""Start a standard python shell"""
import code
try: # readline module is only available on unix systems
import readline
except ImportError:
pass
else:
import rlcompleter # noqa: F401
readline.parse_and_bind("tab:complete")
@wraps(_embed_standard_shell)
def wrapper(namespace=namespace, banner=''):
code.interact(banner=banner, local=namespace)
return wrapper
这段代码虽然简短,但它却是实现 scrapy shell 交互模式的核心方法。接下来,我们将基于上面这些方法来模拟构造一个简化的交互式模式来帮助我们更好的理解这些方法的作用。来看我抽取这些方法,简单编写的一个 test.py 脚本:
[root@server2 shen]# cat test.py
from functools import wraps
def _embed_standard_shell(namespace={}, banner=''):
"""Start a standard python shell"""
import code
try: # readline module is only available on unix systems
import readline
except ImportError:
pass
else:
import rlcompleter # noqa: F401
readline.parse_and_bind("tab:complete")
@wraps(_embed_standard_shell)
def wrapper(namespace=namespace, banner=''):
code.interact(banner=banner, local=namespace)
return wrapper
def start_python_console(namespace=None, banner='', shells=None):
"""Start Python console bound to the given namespace.
Readline support and tab completion will be used on Unix, if available.
"""
if namespace is None:
namespace = {}
try:
shell = _embed_standard_shell()
shell(namespace=namespace, banner=banner)
except SystemExit: # raised when using exit() in python code.interact
pass
start_python_console({'hello': 'world'}, banner='nothing to say')
我们来运行下这个测试脚本看看效果:
[root@server2 shen]# python3 test.py
nothing to say
>>> hello
'world'
>>> xxx
Traceback (most recent call last):
File "<console>", line 1, in <module>
NameError: name 'xxx' is not defined
>>> exit()
是不是和 scrapy shell 交互式一模一样?到此为止,我们对 scrapy shell 这个命令已经分析的非常清楚了,大家是不是已经都理解了呢?
3. 小结
本小节中我们介绍了 Scrapy 框架所支持的部分命令,接着便分析了两个简单的 Scrapy 命令的执行过程,带领大家深入学习了部分 Scrapy 源码,这是我们掌握 Scrapy 框架的第一步,也希望大家好好坚持下去。
- 还没有人评论,欢迎说说您的想法!
 客服
客服


