


GraphX是一个新的(alpha)Spark API,它用于图和并行图(graph-parallel)的计算。GraphX通过引入Resilient Distributed Property Graph:带有 顶点和边属性的有向多重图,来扩展Spark RDD。为了支持图计算,GraphX公开一组基本的功能操作以及Pregel API的一个优化。另外,GraphX包含了一个日益增长的图算法和图builders的 集合,用以简化图分析任务。
从社交网络到语言建模,不断增长的规模和图形数据的重要性已经推动了许多新的graph-parallel系统(如Giraph和GraphLab)的发展。 通过限制可表达的计算类型和引入新的技术来划分和分配图,这些系统可以高效地执行复杂的图形算法,比一般的data-parallel系统快很多。
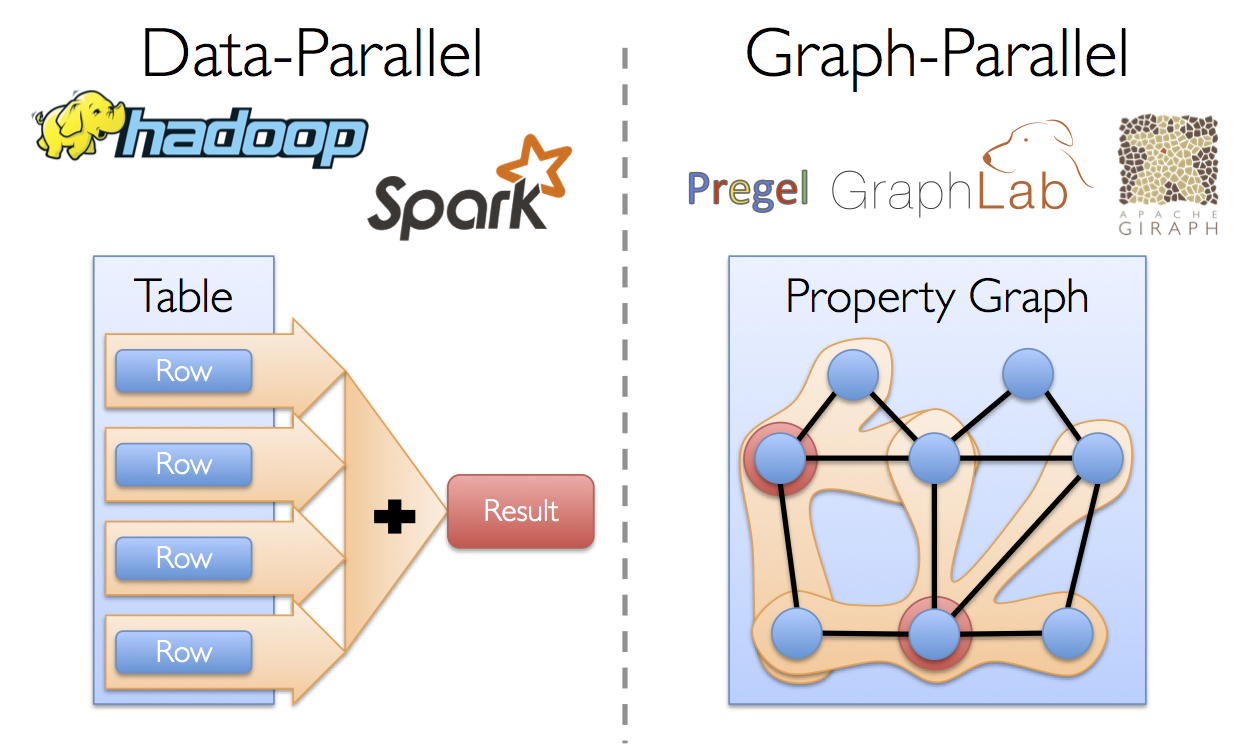
然而,通过这种限制可以提高性能,但是很难表示典型的图分析途径(构造图、修改它的结构或者表示跨多个图的计算)中很多重要的stages。另外,我们如何看待数据取决于我们的目标,并且同一原始数据可能有许多不同表和图的视图。
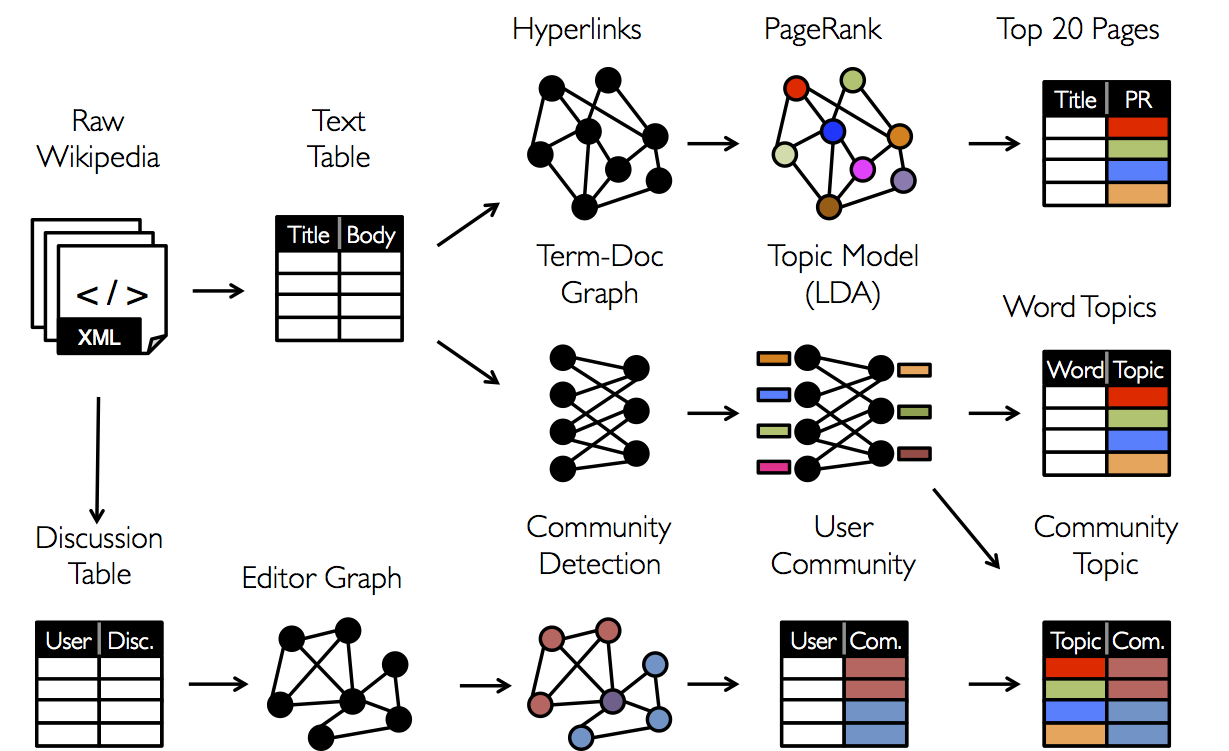
结论是,图和表之间经常需要能够相互移动。然而,现有的图分析管道必须组成graph-parallel和data- parallel系统`,从而实现大数据的迁移和复制并生成一个复杂的编程模型。
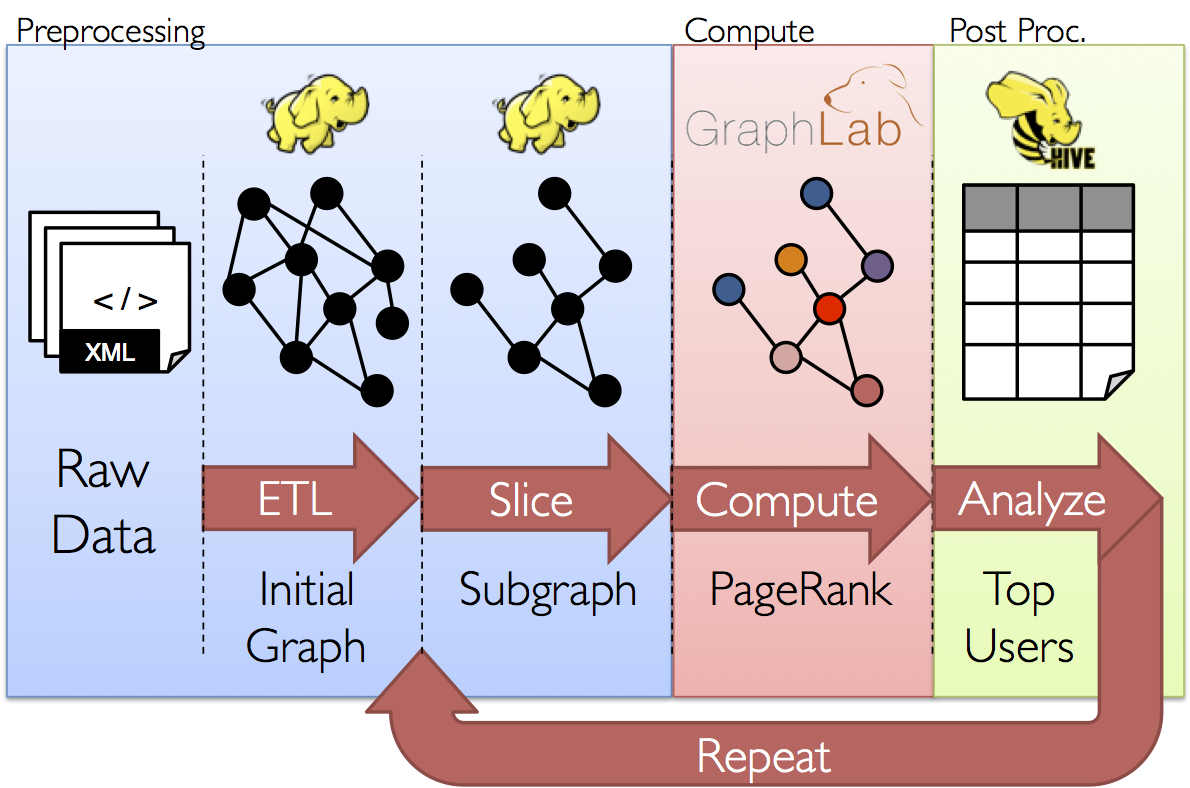
GraphX项目的目的就是将graph-parallel和data-parallel统一到一个系统中,这个系统拥有一个唯一的组合API。GraphX允许用户将数据当做一个图和一个集合(RDD),而不需要 而不需要数据移动或者复杂。通过将最新的进展整合进graph-parallel系统,GraphX能够优化图操作的执行。
- 开始
- 属性图
- 图操作符
- Pregel API
- 图构造者
- 顶点和边RDDs
- 图算法
- 例子
开始
开始的第一步是引入Spark和GraphX到你的项目中,如下面所示
mport org.apache.spark._
import org.apache.spark.graphx._
// To make some of the examples work we will also need RDD
import org.apache.spark.rdd.RDD
如果你没有用到Spark shell,你还将需要SparkContext。
- 还没有人评论,欢迎说说您的想法!
 客服
客服


