


Searchbird
我们要使用 Scala 和先前介绍的 Finagle 框架构建一个简单的分布式搜索引擎。
设计目标:大图景
从广义上讲,我们的设计目标包括 抽象 (abstraction:在不知道其内部的所有细节的前提下,利用该系统功能的能力)、 模块化 (modularity:把系统分解为小而简单的片段,从而更容易被理解和/或被更换的能力)和 扩展性 (scalability:用简单直接的方法给系统扩容的能力)。
我们要描述的系统有三个部分: (1) 客户端 发出请求,(2) 服务端 接收请求并应答,和(3) 传送 机制来这些通信包装起来。通常情况下,客户端和服务器位于不同的机器上,通过网络上的一个特定的端口进行通信,但在这个例子中,它们将运行在同一台机器上(而且仍然使用端口进行通信) 。在我们的例子中,客户端和服务器将用 Scala 编写,传送协议将使用 Thrift 处理。本教程的主要目的是展示一个简单的具有良好可扩展性的服务器和客户端。
探索默认的引导程序项目
首先,使用 scala-bootstrapper 创建一个骨架项目( “ Searchbird ” )。这将创建一个简单的基于 Finagle 和 key-value 内存存储的 Scala 服务。我们将扩展这个工程以支持搜索值,并进而支持多进程多个内存存储的搜索。
$ mkdir searchbird ; cd searchbird
$ scala-bootstrapper searchbird
writing build.sbt
writing config/development.scala
writing config/production.scala
writing config/staging.scala
writing config/test.scala
writing console
writing Gemfile
writing project/plugins.sbt
writing README.md
writing sbt
writing src/main/scala/com/twitter/searchbird/SearchbirdConsoleClient.scala
writing src/main/scala/com/twitter/searchbird/SearchbirdServiceImpl.scala
writing src/main/scala/com/twitter/searchbird/config/SearchbirdServiceConfig.scala
writing src/main/scala/com/twitter/searchbird/Main.scala
writing src/main/thrift/searchbird.thrift
writing src/scripts/searchbird.sh
writing src/scripts/config.sh
writing src/scripts/devel.sh
writing src/scripts/server.sh
writing src/scripts/service.sh
writing src/test/scala/com/twitter/searchbird/AbstractSpec.scala
writing src/test/scala/com/twitter/searchbird/SearchbirdServiceSpec.scala
writing TUTORIAL.md
首先,来看下 scala-bootstrapper 为我们创建的默认项目。这是一个模板。虽然最终将替换它的大部分内容,不过作为支架它还是很方便的。它定义了一个简单(但完整)的 key-value 存储,并包含了配置、thrift 接口、统计输出和日志记录。
在我们看代码之前,先运行一个客户端和服务器,看看它是如何工作的。这里是我们构建的:
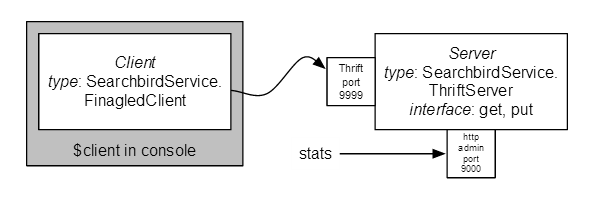
这里是我们的服务输出的接口。由于 Searchbird 服务是一个 Thrift 服务(和我们大部分服务一样),因而其外部接口使用 Thrift IDL(“接口描述语言”)定义。
src/main/thrift/searchbird.thrift
service SearchbirdService {
string get(1: string key) throws(1: SearchbirdException ex)
void put(1: string key, 2: string value)
}
这是非常直观的:我们的服务 SearchbirdService 输出两个 RPC 方法 get 和 put 。他们组成了一个到 key-value 存储的简单接口。
现在,让我们运行默认的服务,启动客户端连接到这个服务,并通过这个接口来探索他们。打开两个窗口,一个用于服务器,一个用于客户端。
在第一个窗口中,用交互模式启动 SBT(在命令行中运行 ./sbt [1]),然后构建和运行项目内 SBT。这会运行 Main.scala 定义的 主 进程。
$ ./sbt
...
> compile
> run -f config/development.scala
...
[info] Running com.twitter.searchbird.Main -f config/development.scala
配置文件 (development.scala) 实例化一个新的服务,并监听 9999 端口。客户端可以连接到 9999 端口使用此服务。
现在,我们将使用 控制台 shell脚本初始化和运行一个客户端实例,即 SearchbirdConsoleClient 实例 (SearchbirdConsoleClient.scala) 。在另一个窗口中运行此脚本:
$ ./console 127.0.0.1 9999
[info] Running com.twitter.searchbird.SearchbirdConsoleClient 127.0.0.1 9999
'client' is bound to your thrift client.
finagle-client>
客户端对象 client 现在连接到本地计算机上的 9999 端口,并可以跟服务交互了。接下来我们发送一些请求:
scala> client.put("marius", "Marius Eriksen")
res0: ...
scala> client.put("stevej", "Steve Jenson")
res1: ...
scala> client.get("marius")
res2: com.twitter.util.Future[String] = ...
scala> client.get("marius").get()
res3: String = Marius Eriksen
(第二个 get() 调用解析 client.get() 返回的 Future 类型值,阻塞直到该值准备好。)
该服务器还输出运行统计(配置文件中指定这些信息在 9900 端口)。这不仅方便对各个服务器进行检查,也利于聚集全局的服务统计(以机器可读的 JSON 接口)。打开第三个窗口来查看这些统计:
$ curl localhost:9900/stats.txt
counters:
Searchbird/connects: 1
Searchbird/received_bytes: 264
Searchbird/requests: 3
Searchbird/sent_bytes: 128
Searchbird/success: 3
jvm_gc_ConcurrentMarkSweep_cycles: 1
jvm_gc_ConcurrentMarkSweep_msec: 15
jvm_gc_ParNew_cycles: 24
jvm_gc_ParNew_msec: 191
jvm_gc_cycles: 25
jvm_gc_msec: 206
gauges:
Searchbird/connections: 1
Searchbird/pending: 0
jvm_fd_count: 135
jvm_fd_limit: 10240
jvm_heap_committed: 85000192
jvm_heap_max: 530186240
jvm_heap_used: 54778640
jvm_nonheap_committed: 89657344
jvm_nonheap_max: 136314880
jvm_nonheap_used: 66238144
jvm_num_cpus: 4
jvm_post_gc_CMS_Old_Gen_used: 36490088
jvm_post_gc_CMS_Perm_Gen_used: 54718880
jvm_post_gc_Par_Eden_Space_used: 0
jvm_post_gc_Par_Survivor_Space_used: 1315280
jvm_post_gc_used: 92524248
jvm_start_time: 1345072684280
jvm_thread_count: 16
jvm_thread_daemon_count: 7
jvm_thread_peak_count: 16
jvm_uptime: 1671792
labels:
metrics:
Searchbird/handletime_us: (average=9598, count=4, maximum=19138, minimum=637, p25=637, p50=4265, p75=14175, p90=19138, p95=19138, p99=19138, p999=19138, p9999=19138, sum=38393)
Searchbird/request_latency_ms: (average=4, count=3, maximum=9, minimum=0, p25=0, p50=5, p75=9, p90=9, p95=9, p99=9, p999=9, p9999=9, sum=14)
除了我们自己的服务统计信息以外,还有一些通用的 JVM 统计。
现在,让我们来看看配置、服务器和客户端的实现代码。
…/config/SearchbirdServiceConfig.scala
配置是一个 Scala 的特质,有一个方法 apply: RuntimeEnvironment => T 来创建一些 T 。在这个意义上,配置是“工厂” 。在运行时,配置文件(通过使用Scala编译器库)被取值为一个脚本,并产生一个配置对象。 RuntimeEnvironment 是一个提供各种运行参数(命令行标志, JVM 版本,编译时间戳等)查询的一个对象。
SearchbirdServiceConfig 类就是这样一个配置类。它使用其默认值一起指定配置参数。 (Finagle 支持一个通用的跟踪系统,我们在本教程将不会介绍: Zipkin 一个集合/聚合轨迹的 分布式跟踪系统。)
class SearchbirdServiceConfig extends ServerConfig[SearchbirdService.ThriftServer] {
var thriftPort: Int = 9999
var tracerFactory: Tracer.Factory = NullTracer.factory
def apply(runtime: RuntimeEnvironment) = new SearchbirdServiceImpl(this)
}
在我们的例子中,我们要创建一个 SearchbirdService.ThriftServer。这是由 thrift 代码生成器生成的服务器类型[2]。
…/Main.scala
在 SBT 控制台中键入“run”调用 main ,这将配置和初始化服务器。它读取配置(在 development.scala 中指定,并会作为参数传给“run”),创建 SearchbirdService.ThriftServer ,并启动它。 RuntimeEnvironment.loadRuntimeConfig 执行配置赋值,并把自身作为一个参数来调用 apply [3]。
object Main {
private val log = Logger.get(getClass)
def main(args: Array[String]) {
val runtime = RuntimeEnvironment(this, args)
val server = runtime.loadRuntimeConfig[SearchbirdService.ThriftServer]
try {
log.info("Starting SearchbirdService")
server.start()
} catch {
case e: Exception =>
log.error(e, "Failed starting SearchbirdService, exiting")
ServiceTracker.shutdown()
System.exit(1)
}
}
}
…/SearchbirdServiceImpl.scala
这是实质的服务:我们用自己的实现扩展 SearchbirdService.ThriftServer 。回忆一下 thrift 为我们生成的 SearchbirdService.ThriftServer 。它为每一个 thrift 方法生成一个 Scala 方法。到目前为止,在我们的例子中生成的接口是:
trait SearchbirdService {
def put(key: String, value: String): Future[Void]
def get(key: String): Future[String]
}
返回值是 Future[Value] 而不是直接返回值,可以推迟它们的计算(finagle 的文档有 Future 更多的细节)。对本教程的目的来说,你唯一需要知道的有关 Future 的知识点是,可以通过 get() 获取其值。
scala-bootstrapper 默认实现的 key-value 存储很简单:它提供了一个通过 get 和 put 访问的 数据库 数据结构。
class SearchbirdServiceImpl(config: SearchbirdServiceConfig) extends SearchbirdService.ThriftServer {
val serverName = "Searchbird"
val thriftPort = config.thriftPort
override val tracerFactory = config.tracerFactory
val database = new mutable.HashMap[String, String]()
def get(key: String) = {
database.get(key) match {
case None =>
log.debug("get %s: miss", key)
Future.exception(SearchbirdException("No such key"))
case Some(value) =>
log.debug("get %s: hit", key)
Future(value)
}
}
def put(key: String, value: String) = {
log.debug("put %s", key)
database(key) = value
Future.Unit
}
def shutdown() = {
super.shutdown(0.seconds)
}
}
其结果是构建在 Scala HashMap 上的一个简单 thrift 接口。
一个简单的搜索引擎
现在,我们将扩展现有的例子,来创建一个简单的搜索引擎。然后,我们将进一步扩展它成为由多个分片组成的 分布式 搜索引擎,使我们能够适应比单台机器内存更大的语料库。
为了简单起见,我们将最小化扩展目前的 thrift 服务,以支持搜索操作。使用模型是用 put 把文件加入搜索引擎,其中每个文件包含了一系列的记号(词),那么我们就可以输入一串记号,然后搜索会返回包含这个串中所有记号的所有文件。该体系结构是与前面的例子相同,但增加了一个新的 @search@ 调用。
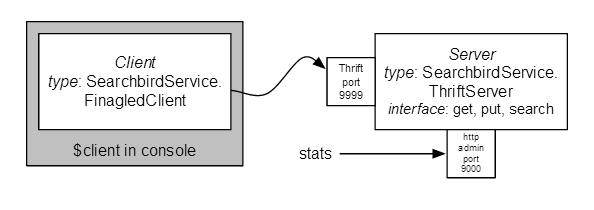
要实现这样一个搜索引擎需要修改以下两个文件:
src/main/thrift/searchbird.thrift
service SearchbirdService {
string get(1: string key) throws(1: SearchbirdException ex)
void put(1: string key, 2: string value)
list<string> search(1: string query)
}
我们增加了一个 search 方法来搜索当前哈希表,返回其值与查询匹配的键列表。实现也很简单直观:
…/SearchbirdServiceImpl.scala
大部分修改都在这个文件中。
现在的 数据库 HashMap 保存一个正向索引来持有到文档的键映射。我们重命名它为 forward 并增加一个 倒排(reverse) 索引(映射记号到所有包含该记号的文件)。所以在 SearchbirdServiceImpl.scala 中,更换 database 定义:
val forward = new mutable.HashMap[String, String]
with mutable.SynchronizedMap[String, String]
val reverse = new mutable.HashMap[String, Set[String]]
with mutable.SynchronizedMap[String, Set[String]]
在 get 调用中,使用 forward 替换 数据库 即可,在其他方面 get 保持不变(仅执行正向查找)。不过 put 还需要改变:我们还需要为文件中的每个令牌填充反向索引,把文件的键附加到令牌关联的列表中。用下面的代码替换 put 调用。给定一个特定的搜索令牌,我们现在可以使用反向映射来查找文件。
def put(key: String, value: String) = {
log.debug("put %s", key)
forward(key) = value
// serialize updaters
synchronized {
value.split(" ").toSet foreach { token =>
val current = reverse.getOrElse(token, Set())
reverse(token) = current + key
}
}
Future.Unit
}
需要注意的是(即使 HashMap 是线程安全的)同时只能有一个线程可以更新倒排索引,以确保对映射条目的 读-修改-写 是一个原子操作。 (这段代码过于保守;在进行 检索-修改-写 操作时,它锁定了整个映射,而不是锁定单个条目。)。另外还要注意使用 Set 作为数据结构;这可以确保即使一个文件中两次出现同样的符号,它也只会被 foreach 循环处理一次。
这个实现仍然有一个问题,作为留给读者的一个练习:当我们用一个新文档覆盖的一个键的时候,我们诶有删除任何倒排索引中引用的旧文件。
现在进入搜索引擎的核心:新的 search 方法。他应该解析查询,寻找匹配的文档,然后对这些列表做相交操作。这将产生包含所有查询中的标记的文件列表。在 Scala 中可以很直接地表达;添加这段代码到 SearchbirdServiceImpl 类中:
def search(query: String) = Future.value {
val tokens = query.split(" ")
val hits = tokens map { token => reverse.getOrElse(token, Set()) }
val intersected = hits reduceLeftOption { _ & _ } getOrElse Set()
intersected.toList
}
在这段短短的代码中有几件事情是值得关注的。在构建命中列表时,如果键( token )没有被发现, getOrElse 会返回其第二个参数(在这种情况下,一个空 Set )。我们使用 left-reduce 执行实际的相交操作。特别是当 reduceLeftOption 发现 hits 为空时将不会继续尝试执行 reduce 操作。这使我们能够提供一个默认值,而不是抛出一个异常。其实这相当于:
def search(query: String) = Future.value {
val tokens = query.split(" ")
val hits = tokens map { token => reverse.getOrElse(token, Set()) }
if (hits.isEmpty)
Nil
else
hits reduceLeft { _ & _ } toList
}
使用哪种方式大多是个人喜好的问题,虽然函数式风格往往会避开带有合理默认值的条件语句。
现在,我们可以尝试在控制台中实验我们新的实现。重启服务器:
$ ./sbt
...
> compile
> run -f config/development.scala
...
[info] Running com.twitter.searchbird.Main -f config/development.scala
然后再从 searchbird 目录,启动客户端:
$ ./console 127.0.0.1 9999
...
[info] Running com.twitter.searchbird.SearchbirdConsoleClient 127.0.0.1 9999
'client' is bound to your thrift client.
finagle-client>
粘贴以下说明到控制台:
client.put("basics", " values functions classes methods inheritance try catch finally expression oriented")
client.put("basics", " case classes objects packages apply update functions are objects (uniform access principle) pattern")
client.put("collections", " lists maps functional combinators (map foreach filter zip")
client.put("pattern", " more functions! partialfunctions more pattern")
client.put("type", " basic types and type polymorphism type inference variance bounds")
client.put("advanced", " advanced types view bounds higher kinded types recursive types structural")
client.put("simple", " all about sbt the standard scala build")
client.put("more", " tour of the scala collections")
client.put("testing", " write tests with specs a bdd testing framework for")
client.put("concurrency", " runnable callable threads futures twitter")
client.put("java", " java interop using scala from")
client.put("searchbird", " building a distributed search engine using")
现在,我们可以执行一些搜索,返回包含搜索词的文件的键。
> client.search("functions").get()
res12: Seq[String] = ArrayBuffer(basics)
> client.search("java").get()
res13: Seq[String] = ArrayBuffer(java)
> client.search("java scala").get()
res14: Seq[String] = ArrayBuffer(java)
> client.search("functional").get()
res15: Seq[String] = ArrayBuffer(collections)
> client.search("sbt").get()
res16: Seq[String] = ArrayBuffer(simple)
> client.search("types").get()
res17: Seq[String] = ArrayBuffer(type, advanced)
回想一下,如果调用返回一个 Future ,我们必须使用一个阻塞的 get() 来获取其中包含的值。我们可以使用 Future.collect 命令来创建多个并发请求,并等待所有请求成功返回:
> import com.twitter.util.Future
...
> Future.collect(Seq(
client.search("types"),
client.search("sbt"),
client.search("functional")
)).get()
res18: Seq[Seq[String]] = ArrayBuffer(ArrayBuffer(type, advanced), ArrayBuffer(simple), ArrayBuffer(collections))
分发我们的服务
单台机器上一个简单的内存搜索引擎将无法搜索超过内存大小的语料库。现在,我们要大胆改进,用一个简单的分片计划来构建分布式节点。下面是框图:
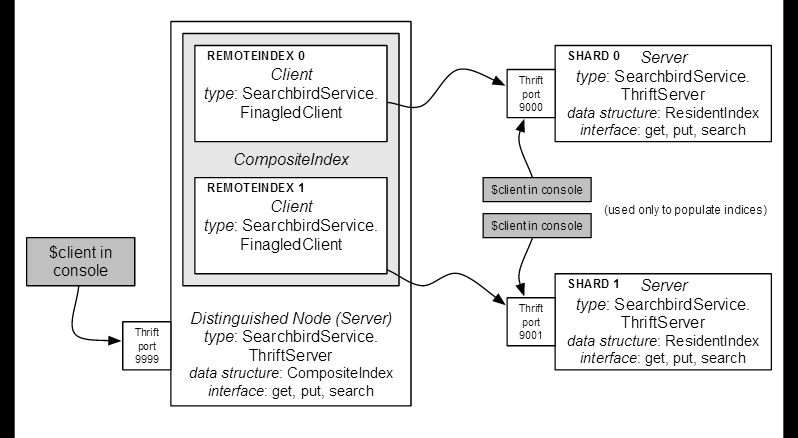
抽象
为了帮助我们的工作,我们会先介绍另一个抽象索引来解耦 SearchbirdService 对索引实现的依赖。这是一个直观的重构。我们首先添加一个索引文件到构建 (创建文件 searchbird/src/main/scala/com/twitter/searchbird/Index.scala ):
…/Index.scala
package com.twitter.searchbird
import scala.collection.mutable
import com.twitter.util._
import com.twitter.conversions.time._
import com.twitter.logging.Logger
import com.twitter.finagle.builder.ClientBuilder
import com.twitter.finagle.thrift.ThriftClientFramedCodec
trait Index {
def get(key: String): Future[String]
def put(key: String, value: String): Future[Unit]
def search(key: String): Future[List[String]]
}
class ResidentIndex extends Index {
val log = Logger.get(getClass)
val forward = new mutable.HashMap[String, String]
with mutable.SynchronizedMap[String, String]
val reverse = new mutable.HashMap[String, Set[String]]
with mutable.SynchronizedMap[String, Set[String]]
def get(key: String) = {
forward.get(key) match {
case None =>
log.debug("get %s: miss", key)
Future.exception(SearchbirdException("No such key"))
case Some(value) =>
log.debug("get %s: hit", key)
Future(value)
}
}
def put(key: String, value: String) = {
log.debug("put %s", key)
forward(key) = value
// admit only one updater.
synchronized {
(Set() ++ value.split(" ")) foreach { token =>
val current = reverse.get(token) getOrElse Set()
reverse(token) = current + key
}
}
Future.Unit
}
def search(query: String) = Future.value {
val tokens = query.split(" ")
val hits = tokens map { token => reverse.getOrElse(token, Set()) }
val intersected = hits reduceLeftOption { _ & _ } getOrElse Set()
intersected.toList
}
}
现在,我们把 thrift 服务转换成一个简单的调度机制:为每一个索引实例提供一个 thrift 接口。这是一个强大的抽象,因为它分离了索引实现和服务实现。服务不再知道索引的任何细节;索引可以是本地的或远程的,甚至可能是许多索引的组合,但服务并不关心,索引实现可能会更改但是不用修改服务。
将 SearchbirdServiceImpl 类定义更换为以下(简单得多)的代码(其中不再包含索引实现细节)。注意初始化服务器现在需要第二个参数 Index 。
…/SearchbirdServiceImpl.scala
class SearchbirdServiceImpl(config: SearchbirdServiceConfig, index: Index) extends SearchbirdService.ThriftServer {
val serverName = "Searchbird"
val thriftPort = config.thriftPort
def get(key: String) = index.get(key)
def put(key: String, value: String) =
index.put(key, value) flatMap { _ => Future.Unit }
def search(query: String) = index.search(query)
def shutdown() = {
super.shutdown(0.seconds)
}
}
…/config/SearchbirdServiceConfig.scala
相应地更新 SearchbirdServiceConfig 的 apply 调用:
class SearchbirdServiceConfig extends ServerConfig[SearchbirdService.ThriftServer] {
var thriftPort: Int = 9999
var tracerFactory: Tracer.Factory = NullTracer.factory
def apply(runtime: RuntimeEnvironment) = new SearchbirdServiceImpl(this, new ResidentIndex)
}
我们将建立一个简单的分布式系统,一个主节点组织查询其子节点。为了实现这一目标,我们将需要两个新的 Index 类型。一个代表远程索引,另一种是其他多个 Index 实例的组合索引。这样我们的服务就可以实例化多个远程索引的复合索引来构建分布式索引。请注意这两个 Index 类型具有相同的接口,所以服务器不需要知道它们所连接的索引是远程的还是复合的。
…/Index.scala
在 Index.scala 中定义了 CompositeIndex :
class CompositeIndex(indices: Seq[Index]) extends Index {
require(!indices.isEmpty)
def get(key: String) = {
val queries = indices.map { idx =>
idx.get(key) map { r => Some(r) } handle { case e => None }
}
Future.collect(queries) flatMap { results =>
results.find { _.isDefined } map { _.get } match {
case Some(v) => Future.value(v)
case None => Future.exception(SearchbirdException("No such key"))
}
}
}
def put(key: String, value: String) =
Future.exception(SearchbirdException("put() not supported by CompositeIndex"))
def search(query: String) = {
val queries = indices.map { _.search(query) rescue { case _=> Future.value(Nil) } }
Future.collect(queries) map { results => (Set() ++ results.flatten) toList }
}
}
组合索引构建在一组相关 Index 实例的基础上。注意它并不关心这些实例实际上是如何实现的。这种组合类型在构建不同查询机制的时候具有极大的灵活性。我们没有定义拆分机制,所以复合索引不支持 put 操作。这些请求被直接交由子节点处理。 get 的实现是查询所有子节点,并提取第一个成功的结果。如果没有成功结果的话,则抛出一个异常。注意因为没有结果是通过抛出一个异常表示的,所以我们 处理Future ,是将任何异常转换成 None 。在实际系统中,我们很可能会为遗漏值填入适当的错误码,而不是使用异常。异常在构建原型时是方便和适宜的,但不能很好地组合。为了把真正的例外和遗漏值区分开,必须要检查异常本身。相反,把这种区别直接嵌入在返回值的类型中是更好的风格。
search 像以前一样工作。和提取第一个结果不同,我们把它们组合起来,通过使用 Set 确保其唯一性。
RemoteIndex 提供了到远程服务器的一个 Index 接口。
class RemoteIndex(hosts: String) extends Index {
val transport = ClientBuilder()
.name("remoteIndex")
.hosts(hosts)
.codec(ThriftClientFramedCodec())
.hostConnectionLimit(1)
.timeout(500.milliseconds)
.build()
val client = new SearchbirdService.FinagledClient(transport)
def get(key: String) = client.get(key)
def put(key: String, value: String) = client.put(key, value) map { _ => () }
def search(query: String) = client.search(query) map { _.toList }
}
这样就使用一些合理的默认值,调用代理,稍微调整类型,就构造出一个 finagle thrift 客户端。
全部放在一起
现在我们拥有了需要的所有功能。我们需要调整配置,以便能够调用一个给定的节点,不管是主节点亦或是数据分片节点。为了做到这一点,我们将通过创建一个新的配置项来在系统中枚举分片。我们还需要添加 Index 参数到我们的 SearchbirdServiceImpl 实例。然后,我们将使用命令行参数(还记得 Config 是如何做到的吗)在这两种模式中启动服务器。
…/config/SearchbirdServiceConfig.scala
class SearchbirdServiceConfig extends ServerConfig[SearchbirdService.ThriftServer] {
var thriftPort: Int = 9999
var shards: Seq[String] = Seq()
def apply(runtime: RuntimeEnvironment) = {
val index = runtime.arguments.get("shard") match {
case Some(arg) =>
val which = arg.toInt
if (which >= shards.size || which < 0)
throw new Exception("invalid shard number %d".format(which))
// override with the shard port
val Array(_, port) = shards(which).split(":")
thriftPort = port.toInt
new ResidentIndex
case None =>
require(!shards.isEmpty)
val remotes = shards map { new RemoteIndex(_) }
new CompositeIndex(remotes)
}
new SearchbirdServiceImpl(this, index)
}
}
现在,我们将调整配置:添加“分片”初始化到 SearchbirdServiceConfig 的初始化中(我们可以通过端口 9000 访问分片 0,9001 访问分片 1,依次类推)。
config/development.scala
new SearchbirdServiceConfig {
// Add your own config here
shards = Seq(
"localhost:9000",
"localhost:9001",
"localhost:9002"
)
...
注释掉 admin.httpPort 的设置(我们不希望在同一台机器上运行多个服务,而不注释的话这些服务都会试图打开相同的端口):
// admin.httpPort = 9900
现在,如果我们不带任何参数调用我们的服务器程序,它会启动一个主节点来和所有分片通信。如果我们指定一个分片参数,它会在指定端口启动一个分片服务器。
让我们试试吧!我们将启动 3 个服务:2 个分片和 1 个主节点。首先编译改动:
$ ./sbt
> compile
...
> exit
然后启动三个服务:
$ ./sbt 'run -f config/development.scala -D shard=0'
$ ./sbt 'run -f config/development.scala -D shard=1'
$ ./sbt 'run -f config/development.scala'
您可以在 3 个不同的窗口中分别运行,或在同一窗口开始依次逐个运行,等待其启动后,只用 ctrl-z 悬挂这个命令,并使用 bg 将它放在后台执行。
然后,我们将通过控制台与它们进行互动。首先,让我们填充一些数据在两个分片节点。从 searchbird 目录运行:
$ ./console localhost 9000
...
> client.put("fromShardA", "a value from SHARD_A")
> client.put("hello", "world")
$ ./console localhost 9001
...
> client.put("fromShardB", "a value from SHARD_B")
> client.put("hello", "world again")
一旦完成就可以退出这些控制台会话。现在通过主节点查询我们的数据库(9999 端口):
$ ./console localhost 9999
[info] Running com.twitter.searchbird.SearchbirdConsoleClient localhost 9999
'client' is bound to your thrift client.
finagle-client> client.get("hello").get()
res0: String = world
finagle-client> client.get("fromShardC").get()
SearchbirdException(No such key)
...
finagle-client> client.get("fromShardA").get()
res2: String = a value from SHARD_A
finagle-client> client.search("hello").get()
res3: Seq[String] = ArrayBuffer()
finagle-client> client.search("world").get()
res4: Seq[String] = ArrayBuffer(hello)
finagle-client> client.search("value").get()
res5: Seq[String] = ArrayBuffer(fromShardA, fromShardB)
这个设计有多个数据抽象,允许更加模块化和可扩展的实现:
- ResidentIndex 数据结构对网络、服务器或客户端一无所知。
- CompositeIndex 对其索引构成的底层数据结构和组合方式一无所知;它只是简单地把请求分配给他们。
- 服务器相同的 search 接口(特质)允许服务器查询其本地数据结构(ResidentIndex) ,或分发到其他服务器(CompositeIndex) 查询,而不需要知道这个区别,这是从调用隐藏的。
- SearchbirdServiceImpl 和 Index 现在是相互独立的模块,这使服务实现变得简单,同时实现了服务和其数据结构之间的分离。
- 这个设计灵活到允许一个或多个远程索引运行在本地机器或远程机器上。
这个实现的可能改进将包括:
- 当前的实现将 put() 调用发送到所有节点。取而代之,我们可以使用一个哈希表,将 put()调用只发送到一个节点,而在所有节点之间分配存储。
- 但是值得注意的是,在这个策略下我们失去了冗余。我们怎样在不需要完全复制的前提下保持一定的冗余度呢?
- 当系统出错时我们没有做任何有趣的处理(例如我们没有处理任何异常)。
[1]本地 ./sbt 脚本只是保证该 SBT 版本和我们知道的所有库是一致的。
[2] 在 target/gen-scala/com/twitter/searchbird/SearchbirdService.scala 。
[3] 更多信息见 Ostrich’s README 。
- 还没有人评论,欢迎说说您的想法!
 客服
客服


